
Developer's Development
3.1.14 [Python] 크롤링 본문
크롤링 (Crawling)
웹 페이지나 API로부터 원하는 정보를 자동으로 수집하는 기술로, 웹 스크래핑이라고도 불린다.
웹 크롤링은 웹 전체를 자동으로 탐색하여 페이지를 수집하는 데 중점을 두며, 주로 검색 엔진에서 활용된다.
vs
웹 스크래핑은 특정 웹 페이지에서 원하는 데이터를 추출하는 데 초점을 맞추며, 데이터 분석 등 특적 목적을 위해 사용된다.
- 필요성 : 데이터 수집 자동화, 실시간 정보 수집, 대규모 데이터 분석, 경쟁력 강화
- 주의 사항 : 법적 고려사항, 서버 부하 방지, 개인정보 보호 및 윤리적 고려, IP 차단 위험
Open API
공개적으로 사용할 수 있도록 제공되는 API로, 개발자가 표준화된 방법으로 특정 서비스나 데이터에 접근할 수 있게 한다.
- 특징 : API 키/OAuth 등의 인증 방식 사용, 사용량 제한/호출 빈도 제한 등의 정책 존재, 공식 문서 제공
- 장점 : 표준화된 인터페이스로 빠르게 개발 가능하여 생산성 향상, 필요한 데이터를 손쉽게 획득하여 서비스 개발에 활용, 데이터 제공자와 소비자 간의 협업과 혁신 촉진
- 사용법
- API 문서 이해
- API 엔드포인트 : API에 접근하기 위한 URL 주소
- HTTP 메서드 : GET(데이터 조회), POST(데이터 생성), PUT/PATCH(데이터 수정), DELETE(데이터 삭제)
- 요청 파라미터 : 쿼리 스트링 또는 요청 본문에 포함되는 데이터
- 응답 형식 : JSON, XML 등으로 데이터 반환
- 인증 방법 : API Key(요청 헤더나 파라미터에 포함), OAuth(토큰 발급 후 인증에 사용)
- API 테스트 방법
API 테스트 도구 사용(Postman 등), cURL 명령어 사용, 브라우저를 통한 간단한 테스트
네이버 API 실습
- 네이버 개발자센터 애플리케이션 등록 (API 이용신청) 👉🏻 Client ID, Client Secret 발급 (사용 API : 검색)
- Documents > 서비스 API > 검색 > 뉴스 실습
https://developers.naver.com/docs/serviceapi/search/news/news.md#%EB%89%B4%EC%8A%A4
검색 > 뉴스 - Search API
검색 > 뉴스 뉴스 검색 개요 개요 검색 API와 뉴스 검색 개요 검색 API는 네이버 검색 결과를 뉴스, 백과사전, 블로그, 쇼핑, 웹 문서, 전문정보, 지식iN, 책, 카페글 등 분야별로 볼 수 있는 API입니다
developers.naver.com
import urllib.parse
import urllib.request
client_id = "발급받은 client_id"
client_secret = "발급받은 client_secret"
text = "AI"
encText = urllib.parse.quote(text) # UTF-8로 인코딩
url = "https://openapi.naver.com/v1/search/news.json?query=" + encText
request = urllib.request.Request(url)
request.add_header("X-Naver-Client-Id", client_id)
request.add_header("X-Naver-Client-Secret", client_secret)
response = urllib.request.urlopen(request)
print(response.getcode()) # 응답상태 코드
response_body = response.read() # 응답 내용
print(response_body.decode('utf-8'))
WEB의 구조
기본 구성 요소 : URL, HTTP/HTTPS 프로토콜, HTML, CSS, JavaScript
HTML 문서 구조 : 기본(<!DOCTYPE html>, <html>, <head>, <body>), DOM
웹의 연결성 요소 : 하이퍼링크, 웹 그래프, 크롤러 탐색
- HTTP 요청과 응답
요청 메서드 : GET, POST, PUT/PATCH, DELETE
상태 코드 : 2XX(성공), 3XX(리다이렉션), 4XX(클라이언트 오류), 5XX(서버 오류)
헤더 : 요청 및 응답에 대한 메타정보 포함(User-Agent, Accept, Content-Type 등)
크롤링 데이터 저장
- 데이터 저장 시 고려사항
데이터의 특성 파악, 데이터의 활용 목적을 명확히 하여 저장 방식 선정, 보안 및 개인정보 보호 유의, 정확성과 완전성 확인 뒤 저장, 에러를 기록하고 모니터링하는 전략 수립, 버전 관리 체계 수립, 확장성을 고려하여 저장소를 선택 및 설계
- 데이터 저장 방식 종류
파일 시스템, 관계형 데이터베이스, NoSQL 데이터베이스 등
브라우저의 동작
- 브라우저의 기본 구조
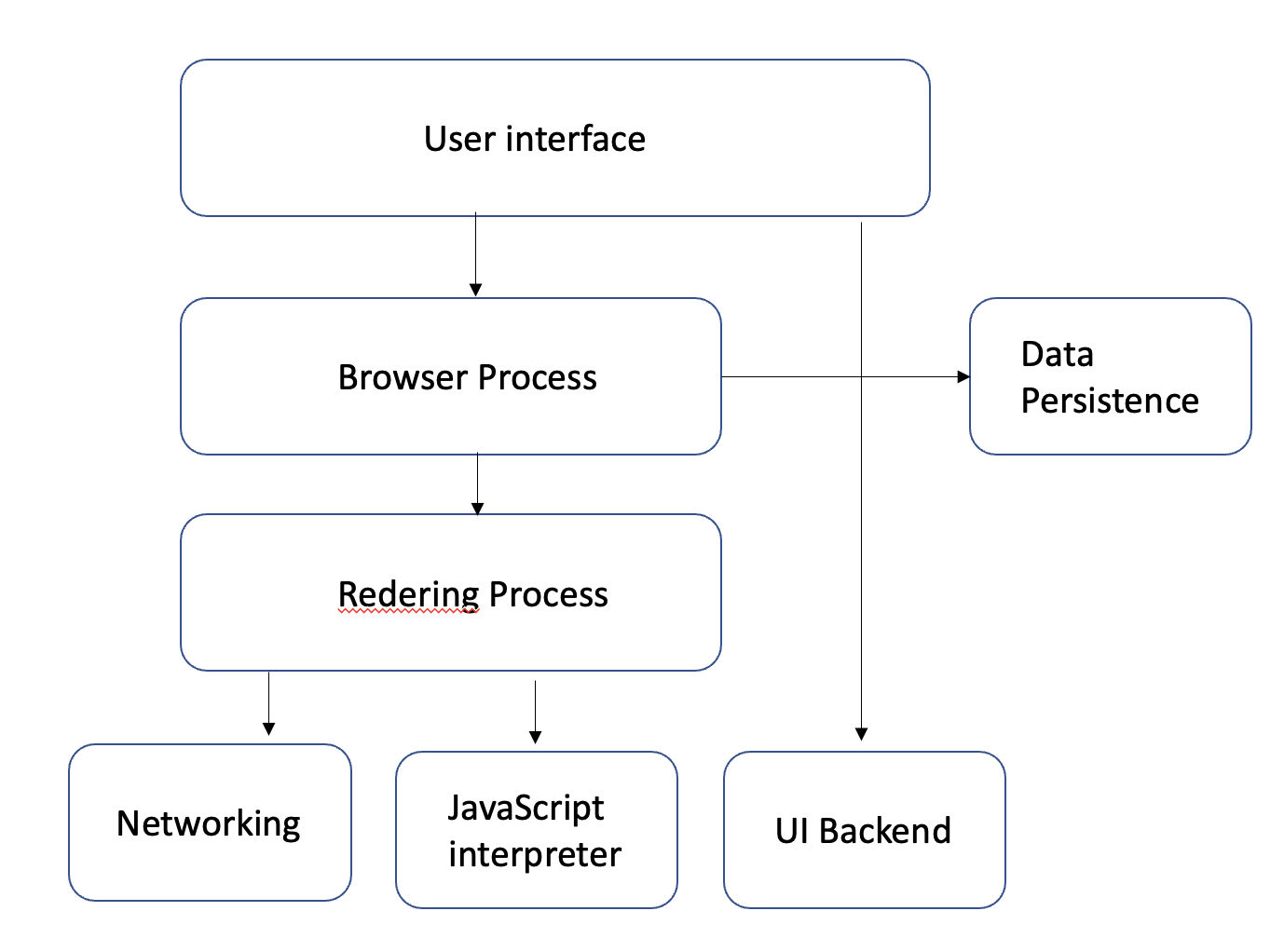
- 렌더링 엔진의 동작 과정
[ DOM Tree, CSSOM Tree 👉🏻 Render Tree 생성 👉🏻 Layout 👉🏻 Paint ]
- HTML 파일과 CSS 파일을 파싱해서 트리 생성
- 두 개의 Tree를 결합하여 Render Tree 생성
- Render Tree에서 각 노드의 위치와 크기를 계산
- 화면 상에 실제 픽셀로 변환하고 레이어를 생산
- 레이어를 생성하여 실제 화면에 표시
크롤링 도구
파이썬 크롤링 라이브러리 종류 : Requests, BeautifulSoup, Selenium, Scrapy, Playwright, Pyppeteer, lxml
- BeautifulSoup : 정적 웹 페이지의 데이터 수집
- Selenium : 동적 웹 페이지의 데이터 수집
- BeautifulSoup
Python 기반의 HTML, XML 파일을 파싱하여 데이터를 추출하는 라이브러리
이미 다운로드된 HTML 문서를 파싱하여 DOM 트리를 생성하고, DOM 트리를 탐색하여 원하는 태그나 속성에 접근하고 데이터를 추출한다.
pip install beautifulsoup4
https://tedboy.github.io/bs4_doc/generated/generated/bs4.BeautifulSoup.html
bs4.BeautifulSoup
tedboy.github.io
- .HTML 문서 파싱 및 초기화 관련
1. BeautifulSoup(markup, parser) : HTML/XML 데이터를 파싱하여 Beautiful 객체를 생성
- 요소 탐색 관련
- soup.find() : html 태그 및 속성을 dict로 조회 (1개만 조회)
- soup.find_all() : html 태그 및 속성을 dict로 조회 (전부 다 조회)
- soup_select(css_selector) : CSS 선택자로 요소를 찾는다.
- soup.select_one(css_selector) : CSS 선택자로 찾은 첫 번째 요소를 반환한다.
# 정적 페이지 웹 스크래핑 -> requests, beautifulsoup
# 정적 페이지 = 요청한 url에서 응답받은 html을 그대로 사용한 경우
# (Server Side Rendering)
import requests
from bs4 import BeautifulSoup
# web request 요청 함수
def web_request(url):
response = requests.get(url) # <Response [200]>
print(response.status_code) # 응답코드
print(response.text) # html
return response
# url = "https://www.naver.com"
# response = web_request(url)
with open('../html_sample.html', 'r', encoding='utf-8') as f:
html = f.read()
# BeautifulSoup 객체 활용
bs = BeautifulSoup(html, 'html.parser')
# print(bs)
# print(type(bs)) # <class 'bs4.BeautifulSoup'>
def test_find():
# find()
tag = bs.find('li')
print(tag)
print(type(tag))
# find_all()
tags = bs.find_all('section', {'id':'section1'})
print(tags)
print(type(tags))
def test_selector():
tag = bs.select_one('section#section2')
print(tag)
print(type(tag)) # <class 'bs4.element.Tag'>
tags = bs.select('.section-content')
print(tags)
print(type(tags)) # <class 'bs4.element.ResultSet'>
def get_content1():
# id가 section2인 section 태그의 후손 li 태그'들'의 내용 출력
tags = bs.select('section#section2 li')
for tag in tags:
print(tag.text)
def get_content2():
# id가 section2인 section 태그의 자식 h2 태그의 '내용', p 태그의 '내용' 출력
h2_tag = bs.select_one('section#section2 > h2')
print(h2_tag.text) # tag element
p_tag = bs.select('section#section1 > p')
for tag in p_tag:
print(tag.text)
def get_content3():
# id가 section1인 section 태그의 자식 태그 조회 -> 내용 출력
section_tag = bs.select_one('section#section1')
children = section_tag.findChildren()
print(children)
# 번외
h2_tag = section_tag.select_one('h2')
p_tags = section_tag.select('p')
print(h2_tag.text)
print((p_tags.text for p_tag in p_tags))
# 함수 실행
# test_find()
# test_selector()
# get_content1()
# get_content2()
get_content3()
- Selenium
브라우저를 자동화하는 도구로, 웹 페이지의 JavaScript 렌더링까지 처리할수 있다.
브라우저 드라이버를 사용하여 실제 브라우저를 구동하여 웹 페이지를 로드하고, 스크립트를 통해 브라우저 내에서 클릭, 입력 등의 동작을 자동화한다. JavaScript 실행을 통해 생성된 콘텐츠도 로드하여 처리할 수 있다.
따라서, 웹 페이지의 인터랙션과 동적 데이터를 크롤링하는 데 유용하다.
chromedriver.exe 파일 준비 및 selenium 설치
pip install selenium# 동적 페이지 웹 크롤링 -> Selenium
# 동적 페이지 : 요청한 URL에서 응답받은 HTML 안의 JS를 실행해 HTML을 새로 만든 경우 (Client Side Rendering)
# Selenium
# - 인증을 요구하는 특정 웹 페이지의 데이터 스크랩
# - 무한 댓글 스크랩
# - 브라우저용 매크로
from selenium import webdriver
from selenium.webdriver.common.by import By
from selenium.webdriver.common.keys import Keys
import time
# 1. chrome 브라우저 실행
path = 'chromedriver.exe'
service = webdriver.chrome.service.Service(path)
driver = webdriver.Chrome(service=service)
# 2. 특정 url 접근
# driver.get("https://search.naver.com/search.naver?ssc=tab.news.all&where=news&sm=tab_jum&query=%ED%81%AC%EB%A1%A4%EB%A7%81")
driver.get('https://naver.com')
time.sleep(1)
# - 검색어 입력 및 검색
search_box = driver.find_element(By.ID, 'query')
search_box.send_keys('크롤링')
search_box.send_keys(Keys.RETURN) # 키보드의 enter 역할
time.sleep(1)
# - 뉴스 탭 이동
next_btn = driver.find_element(By.XPATH, '//*[@id="lnb"]/div[1]/div/div[1]/div/div[2]/div[2]/a/span') # 탭 이동 버튼의 Copy XPATH
next_btn.click()
time.sleep(1)
news_btn = driver.find_element(By.XPATH, '//*[@id="lnb"]/div[1]/div/div[1]/div/div[1]/div[9]/a') # 뉴스 탭 버튼의 Copy XPATH
news_btn.click()
time.sleep(1)
# - 스크롤 처리
for _ in range(5):
body = driver.find_element(By.TAG_NAME, "body")
body.send_keys(Keys.END)
time.sleep(1)
# 3. 데이터 가져오기
news_contents_elems = driver.find_elements(By.CSS_SELECTOR, 'span.sds-comps-text-type-headline1')
for news_contents_elem in news_contents_elems:
parent = news_contents_elem.find_element(By.XPATH, "..") # XPATH에서 ..은 상위를 의미함
title = news_contents_elem.text
href = parent.get_attribute('href')
print(title, "|", href)
# 4. 브라우저 종료 (드라이버 종료)
driver.quit()'프로그래밍과 데이터 기초 > PYTHON' 카테고리의 다른 글
| 3.1.7 [Python] Streamlit (5) | 2025.07.02 |
|---|---|
| 3.1.6 [Python] 예외 (2) | 2025.07.02 |
| 3.1.5 [Python] 모듈&패키지, 파일 IO (0) | 2025.07.01 |
| 3.1.4 [Python] 클래스 (1) | 2025.06.30 |
| 3.1.3 [Python] 함수 (2) | 2025.06.27 |
