
Developer's Development
3.2.2 [데이터 분석] NumPy 본문
Numerical Python의 줄임말로, 대규모 다차원 배열과 행렬 연산을 지원하는 파이썬 라이브러리
수학적 연산을 빠르고 효율적으로 수행할 수 있도록 설계되어 있어, 데이터 분석, 머신러닝, 인공지능, 이미지 처리, 신호 처리, 통계 분석 등 여러 분야에서 활용된다.
⭐ NumPy의 핵심 자료 구조인 ndarray는 다차원 배열을 효율적으로 관리할 수 있다.
⭐ 벡터화 연산을 통해 for문을 사용하지 않고 배열 간 연산을 빠르게 수행할 수 있다.
⭐ Python 리스트는 여러 자료형을 저장할 수 있지만, Numpy 배열은 고정된 자료형을 사용해 메모리를 효율적으로 사용한다.
pip install numpy
ndarray 생성
NumPy의 핵심 자료 구조로, n차원 배열을 의미한다. Python의 리스트와 유사하지만, 고정된 크기와 단일 데이터 타입을 가진다.
배열의 각 차원을 축(axis) 이라고 하며, 각 축의 크기는 배열의 모양(shape) 이다.
속성 👉🏻 shape (배열의 모양), ndim (배열의 차원), size (배열의 크기), dtype (배열의 데이터 타입 확인)
import numpy as np
today_arr = [2025, 7, 16, 11, 32]
arr = np.array([2025, 7, 16, 11, 32]) #리스트로부터 생성
print(today_arr, type(today_arr)) # [2025, 7, 16, 11, 32] <class 'list'>
print(arr, type(arr)) # [2025 7 16 11 32] <class 'numpy.ndarray'>arr = np.array((1, 2, 3, 4, 5)) #튜플로부터 생성
print(arr, type(arr))
# ndarray의 구조를 확인
print(arr.shape) # (5,) /형태: 축이 하나인데 요소가 다섯개(축별로 갯수)이며, 튜플은 콤마가 찍힌 것으로 구분함
print(arr.ndim) # 1 /깊이(축의 갯수)
print(arr.size) # 5 /요소의 갯수
print(arr.dtype) # int64 /요소의 자료형
arr_2d = np.array([[1, 2, 3], [4, 5, 6]]) # 2차원 배열로부터 생성
print(arr_2d) # [[1 2 3]
# [4 5 6]] /2차원의 모양새를 갖춤
print([[1, 2, 3], [4, 5, 6]]) # [[1, 2, 3], [4, 5, 6]]
print(arr_2d.shape) # (2, 3)
print(arr_2d.ndim) # 2
print(arr_2d.size) # 6
print(arr_2d.dtype) # int64arr_int = np.array([2025, 7, 14])
print(arr_int.dtype) # int64
arr_float = np.array([1.234, 3.456, 9.876])
print(arr_float.dtype) #float64
arr_bool = np.array([True, False, True, True])
print(arr_bool.dtype) # bool
arr_str = np.array(['Hello', 'World', 'python', 'numpy-lib'])
print(arr_str.dtype) # <U9 /유니코드 9글자까지 저장 가능한 문자열# 형변환
arr = np.array([1.234, 3.456, 9.876, 10])
print(arr.dtype) # float64 /정수 10은 실수로 암묵적 형변환
arr = np.array([1.234, 3.456, 9.876, 10], dtype=float)
print(arr, arr.dtype) # [ 1.234 3.456 9.876 10. ] float64 /명시적 형변환
arr = np.array([1.234, 3.456, 9.876, 10], dtype=int)
print(arr, arr.dtype) # [ 1 3 9 10] int64
arr = arr.astype(float)
print(arr, arr.dtype) # [ 1. 3. 9. 10.] float64
- python list와 ndarray의 차이
ndarray는 동일한 자료형만 저장 가능
ndarray는 다차원인 경우, 중첩 배열은 동일한 크기만 허용
형태/길이를 확인하는 방법
👉🏻 python list: len()
👉🏻 ndarray: ndarray.shape, ndarray.ndim, ndarray.size
my_list = [2025, 7, 14, 'numpy', True]
print(my_list) # [2025, 7, 14, 'numpy', True]
my_list = [[1, 2, 3], [4, 5], [6]]
print(my_list) # [[1, 2, 3], [4, 5], [6]]
print(len(my_list)) # 3
print(len(my_list[0])) # 3arr = np.array([2025, 7, 14, 'numpy', True])
# arr = np.array([[1, 2, 3], [4, 5], [6]]) # ValueError
print(arr) # ['2025' '7' '14' 'numpy' 'True']
print(arr.shape) # (5,)
print(arr.ndim) # 1
print(arr.size) # 5
print(arr.dtype) # <U21
- 특정 수로 초기화된 ndarray 생성
np.zeros() : 모든 값을 0으로 채운 배열 생성
np.ones() : 모든 값을 1로 채운 배열 생성
# zeros
arr = np.zeros((3, 4)) # 인자로 튜플을 전달, shape을 넣어줌
print(arr) # [[0. 0. 0. 0.]
# [0. 0. 0. 0.]
# [0. 0. 0. 0.]]
# ones
arr = np.ones((5, 2))
print(arr) #[[1. 1.]
# [1. 1.]
# [1. 1.]
# [1. 1.]
# [1. 1.]]
# full
arr = np.full((4, 1), 9) # 인자로 shape과 채울 숫자를 함께 넘김
print(arr) # [[9]
# [9]
# [9]
# [9]]
arr = np.full((4,), 9) # 1차원으로도 가능! 콤마를 생략해도 동작은 하지만, 명시적으로 튜플이라는 걸 늘 보여주는 게 좋음
print(arr) # [9 9 9 9]
_like들은 원래 arr의 dtype을 따라감
arr = np.array([[10, 10], [30, 40]])
print(arr.shape) # (2, 2)
# zeros_like
print(np.zeros_like(arr)) # [[0 0]
# [0 0]]
# ones_like
print(np.ones_like(arr)) # [[1 1]
# [1 1]]
# full_like
print(np.full_like(arr, 9)) # [[9 9]
# [9 9]]
- 수열 생성
np.arrange(start, end, step)
👉🏻 start: 시작하는 숫자, end: 끝나는 숫자 + 1, step: start~end 증가하는 간격
arr = np.arange(1, 10) # [1 2 3 4 5 6 7 8 9]
arr = np.arange(1, 10, .1) # [1. 1.1 1.2 1.3 1.4 1.5 1.6 1.7 1.8 1.9 2. 2.1 2.2 2.3 2.4 2.5 2.6 2.7
# 2.8 2.9 3. 3.1 3.2 3.3 3.4 3.5 3.6 3.7 3.8 3.9 4. 4.1 4.2 4.3 4.4 4.5
# 4.6 4.7 4.8 4.9 5. 5.1 5.2 5.3 5.4 5.5 5.6 5.7 5.8 5.9 6. 6.1 6.2 6.3
# 6.4 6.5 6.6 6.7 6.8 6.9 7. 7.1 7.2 7.3 7.4 7.5 7.6 7.7 7.8 7.9 8. 8.1
# 8.2 8.3 8.4 8.5 8.6 8.7 8.8 8.9 9. 9.1 9.2 9.3 9.4 9.5 9.6 9.7 9.8 9.9]
arr = np.arange(10) # [0 1 2 3 4 5 6 7 8 9]
print(arr)
np.linspace(start, end, num)
👉🏻 start: 시작하는 숫자, end: 끝나는 숫자, num: 결과로 만들어진 수열의 요소 개수 (동일한 간격으로 생성, 기본값은 50)
arr = np.linspace(0, 10, 5)
arr = np.linspace(0, 10) # [ 0. 0.20408163 0.40816327 0.6122449 0.81632653 1.02040816
# 1.2244898 1.42857143 1.63265306 1.83673469 2.04081633 2.24489796
# 2.44897959 2.65306122 2.85714286 3.06122449 3.26530612 3.46938776
# 3.67346939 3.87755102 4.08163265 4.28571429 4.48979592 4.69387755
# 4.89795918 5.10204082 5.30612245 5.51020408 5.71428571 5.91836735
# 6.12244898 6.32653061 6.53061224 6.73469388 6.93877551 7.14285714
# 7.34693878 7.55102041 7.75510204 7.95918367 8.16326531 8.36734694
# 8.57142857 8.7755102 8.97959184 9.18367347 9.3877551 9.59183673
# 9.79591837 10. ]
# arr = np.linspace(10) # TypeError
print(arr) # [ 0. 2.5 5. 7.5 10. ]
np.logspace(start_exp, end_exp, num, base)
👉🏻 start_exp: 시작 지수, end_exp: 끝 지수, num: 결과로 만들어진 수열의 요소 개수, base: 밑 (기본값은 10)
arr = np.logspace(1, 3, 4)
print(arr) # [ 10. 46.41588834 215.443469 1000. ]
ndarray indexing & slicing
Python의 리스트처럼 ndarray도 인덱스를 사용하여 배열의 특정 값을 선택할 수 있다.
NumPy 배열은 0부터 시작하는 인덱스를 사용하며, 다차원 배열에서도 각 차원별로 인덱스를 지정할 수 있다.
# 1차원 배열 인덱싱
arr = np.arange(1, 11)
print(arr) # [ 1 2 3 4 5 6 7 8 9 10]
print(arr[1], arr[3], arr[9]) # 2 4 10
print(arr[-1], arr[-5]) # 10 6# 2차원 배열 인덱싱
arr_2d = np.array([[10, 20, 30], [40, 50, 60]])
print(arr_2d.shape) # (2, 3)
print(arr_2d[0]) # [10 20 30]
# 아래 3개 모두 같은 결과
print(arr_2d[0][1])
print(arr_2d[0, 1])
print(arr_2d[(0, 1)]) # 20
arr_2d = np.array([[11, 22, 33], [44, 55, 66], [77, 88, 99]])
print(arr_2d[1, 0]) # 44
print(arr_2d[2, 1]) # 88
print(arr_2d[-1, -2]) # 88 (음수 인덱스 활용)
Python 리스트의 슬라이싱과 유사하게 ndarray도 : 를 사용하여 슬라이싱을 할 수 있다.
# 1차원 배열 슬라이싱
arr = np.arange(1, 11)
print(arr[2:7]) # [3 4 5 6 7]
print(arr[::2]) # [1 3 5 7 9]
print(arr[4:]) # [5 6 7 8 9 10]
print(arr[:-3]) # [1 2 3 4 5 6 7]
print(arr[::-1]) # [10 9 8 7 6 5 4 3 2 1]# 2차원 배열 슬라이싱
arr_2d = np.array([[10, 20, 30], [40, 50, 60], [70, 80, 90]])
print(arr_2d)
print(arr_2d[0:2, 1:2]) # [행 슬라이싱, 열 슬라이싱]
print(arr_2d[0:2, :])
print(arr_2d[:, 1:])
print(arr_2d[0:2])
# 슬라이싱 = shape 유지 (차원 유지)
print(arr_2d[:-1, 0:1]) # [[10]
# [40]]
print(arr_2d[:-1, 0:1].shape) # (2, 1)
# index 접근 -> 값을 꺼내서 반환 (차원 제거)
print(arr_2d[:-1, 0]) # [10 40]
print(arr_2d[:-1, 0].shape) # (2,)
- fancy indexing & boolean indexing
팬시 인덱싱을 통해 정수 배열을 사용하여 여러 위치의 값을 한 번에 선택할 수 있다.
# 1차원 배열 fancy indexing
arr = np.arange(5, 31, 5)
print(arr) # [ 5 10 15 20 25 30]
indices = [1, 3, 5]
print(arr[indices]) # [10 20 30]# 2차원 배열 fancy indexing
arr_2d = np.array([
[5, 10, 15, 20],
[25, 30, 35, 40],
[45, 50, 55, 60]
])
# [10 35]
indices1 = [0, 1]
indices2 = [1, 2]
print(arr_2d[indices1, indices2]) # [10 35]
불리언 인덱싱은 조건을 만족하는 배열의 요소를 선택하는 방법이다.
# 1차원 배열 boolean indexing
arr = np.arange(1, 6)
print(arr) # [1 2 3 4 5]
bools = [True, False, False, False, True]
print(arr[bools]) # [1 5]
print(arr[arr < 3]) # [1 2]# 2차원 배열 boolean indexing
arr_2d = np.array([
[5, 10, 15, 20],
[25, 30, 35, 40],
[45, 50, 55, 60]
])
print(arr_2d[(arr_2d > 30) & (arr_2d < 50)]) # [35 40 45]
print(arr_2d[arr_2d % 2 == 0]) # [10 20 30 40 50 60]
np.all() : ndarray의 모든 요소가 조건을 만족할 때 True 반환
np.any() : ndarray의 요소 중 하나라도 조건을 만족할 때 True 반환
arr = np.array([10, 20, 30, 40, -50])
print(np.all(arr > 0)) # False
print(np.any(arr > 0)) # True
ndarray 연산
- 기본 연산
arr_a = np.arange(1, 10).reshape(3, 3) # 요소의 개수가 맞아야 함
arr_b = np.full_like(arr_a, 7)
# 덧셈
print(arr_a + arr_b)
print(np.add(arr_a, arr_b))
# 뺄셈
print(arr_a - arr_b)
print(np.subtract(arr_a, arr_b))
# 곱셈
print(arr_a * arr_b)
print(np.multiply(arr_a, arr_b))
# 나눗셈
print(arr_a / arr_b)
print(np.divide(arr_a, arr_b))
# 특수연산 1: 몫 연산
print(arr_a // arr_b)
print(np.floor_divide(arr_a, arr_b))
# 특수연산 2: 나머지 연산
print(arr_a % arr_b)
print(np.mod(arr_a, arr_b))
# 특수연산 3: 거듭제곱
print(arr_a ** arr_b)
print(np.power(arr_a, arr_b))
print(np.square(arr_a)) # 제곱연산
print(np.sqrt(arr_a)) # 루트
- 브로드캐스팅(Broadcasting) 연산
두 배열의 shape이 다르면 broadcasting을 수행한다.
shape이 작은 쪽이 큰 쪽에 맞춰 확장한다.
두 배열의 차원의 크기가 같거나, 하나가 1이면 브로드캐스팅이 가능하다.
크기가 1인 차원은 상대 배열의 해당 차원 크기와 다를 경우 자동으로 확장 가능하다.
shape이 다른 경우 마지막 축부터 차원이 동일한지 비교한다.
1. 스킬라 값과의 연산
👉🏻 배열 전체에 스킬라 값을 적용하여 연산할 수 있다.
result_arr = arr_a * np.array([[5,5,5],[5,5,5],[5,5,5]])
result_arr = arr_a * np.array([5,5,5])
result_arr = arr_a * np.array([5])
result_arr = arr_a * 5 # 스칼라 값
print(result_arr) # [[ 5 10 15]
# [20 25 30]
# [35 40 45]]
2. 다차원 배열과 1차원 배열 간의 브로드캐스팅
👉🏻 다차원 배열에 1차원 배열을 브로드캐스팅 하여 연산할 수 있다.
arr1 = np.array([[1,2,3],[4,5,6]])
arr_2 = np.array([5,10,100])
arr1 + arr_2 # array([[ 6, 12, 103],
# [ 9, 15, 106]])
- 행렬 곱셈
👉🏻 점곱 연산 (Dot Product / 내적)
내적은 두 배열의 각 원소를 곱한 후, 그 결과를 모두 더한 값을 계산하는 연산이다.
두 행렬 A, B의 점곱은 첫 번째 행렬 A의 행과 두 번째 행렬 B의 열간 곱셈을 수행한다.
첫 번째 행렬 A의 열의 수와 두 번째 행렬 B의 행의 수가 같아야 한다.
연산 결과의 shape은 (첫 번째 행렬 A의 행 개수, 두 번째 행렬 B의 열 개수)이다.
arr1 = np.array([[1,2],[3,4]])
arr2 = np.array([[5,6],[7,8]])
print(arr1)
print(arr2)
# 기본곱셈
print(arr1 * arr2) # [[ 5 12]
# [21 32]]
# 내적
print(np.dot(arr1, arr2)) # [[19 22]
# [43 50]]arr3 = np.array([[1,2,3],[4,5,6]])
arr4 = np.array([[7,8],[9,10],[11,12]])
print(np.dot(arr3, arr4))
# @
print(arr3 @ arr4) # [[ 58 64]
# [139 154]]# print(arr3 @ arr3) # (2, 3) (2, 3) == 내적 안됨
# .T = 전치행렬 (행-열을 교환)
print(arr3.T)
print(arr3 @ arr3.T)
# matmul()
print(np.matmul(arr3, arr3.T))
- 연산 함수 및 집계 함수
arr_negative = np.array([[-1, -2], [-100, -200]])
arr_float = np.array([[1.234, -5.678], [-7.89, 10.123]])
arr = np.arange(1, 7).reshape(2, 3)
# 올림
print(np.ceil(arr_float))
# 반올림
print(np.round(arr_float))
# 내림 (지정된 수(요소)보다 작은 최대 정수)
print(np.floor(arr_float))
# 버림 (절삭)
print(np.trunc(arr_float))
# 절대값
np.abs(arr_negative)
# 최대값/최소값
print(np.max(arr))
print(np.min(arr))
# 축(axis)을 기준으로 한 연산
print(np.max(arr, axis=0)) # 기준 == 행
print(np.min(arr, axis=1)) # 기준 == 열
# 합계
print(np.sum(arr))
print(arr.sum(axis=0))
print(arr.sum(axis=1))
# 평균
print(np.mean(arr))
print(arr.mean(axis=0))
print(arr.mean(axis=1))
Numpy 통계 관련
- 중심 경향 측도
최빈값의 경우 scipy.stats 패키지를 이용해 계산할 수 있지만, NumPy를 활용해 계산해본 예제
height = np.array((160, 170, 180, 172, 164, 152, 148, 192, 187, 177, 166, 152, 156, 176, 189))
# 평균값
np.mean(height)
# 중위값
np.median(height)
np.sort(height) # 중위값 맞는지 데이터 확인용
# 최빈값 (데이터에서 가장 자주 등장하는 값)
values, count = np.unique(height, return_counts=True) # return_counts를 True로 줄 경우, 반환값 2개
max_count = np.max(count)
print(values[count == max_count]) # 152
- 산포 측도
분산 : 데이터가 평균으로부터 얼마나 떨어져 있는지를 나타내는 지표로, 값이 클수록 데이터가 퍼져 있음을 의미한다.
표준편차 : 분산의 제곱근으로, 데이터의 퍼짐 정도를 나타낸다.
범위 : 데이터의 최댓값과 최솟값의 차이를 의미한다.
# 분산 variance
# (값 - 평균)^2의 평균
print(np.var(height))
# 표준편차 standard deviation
# 분산의 제곱근
print(np.std(var))
# 범위
# 최대값 - 최소값
print(np.max(height) - np.min(height))
- 확률분포
확률 변수가 가질 수 있는 값과 그 값이 나올 확률을 나타내는 함수이다.
pip install matplotlibimport matplotlib.pyplot as plt
# 표준 정규분포: 평균이 0, 표준편차 1
arr = np.random.randn(1000) # 평균 0, 표준편차 1인 정규분포 난수 1000개
plt.hist(arr, bins=100)
plt.show()
정규분포
👉🏻 평균을 중심으로 데이터가 대칭적으로 분포하며, 종 모양의 분포를 나타낸다. 정규분포에서는 평균 근처의 값이 자주 나타나고, 양 끝으로 갈수록 빈도가 감소한다.
# 정규분포
# np.random.normal(loc, scale, size)
# - loc: 평균
# - scale: 표준편차
# - size: 갯수 or shape
arr = np.random.normal(10, 1, (10, 10))
print(arr.shape)
plt.hist(arr, bins=10)
plt.show()
균등분포
👉🏻 모든 값이 동일한 확률도 발생하는 분포를 의미한다.
# 균등분포
# np.random.rand(num)
# - 0.0 이상 1.0 미만 수에서 균등하게 난수 추출
# - num: 개수 or shape
arr = np.random.rand(1000)
arr = np.random.rand(2, 3)
print(arr)
print(np.max(arr), np.min(arr))
plt.hist(arr, bins=10)
plt.show()
# 균등분포
# np.random.randint(start, end, size)
# - start 이상 end 미만의 난수(정수)를 size(shape)만큼 추출
np.random.seed(0) # 난수 계산 시작값 seed 고정
arr = np.random.randint(1, 100, 1000)
arr = np.random.randint(1, 100, (2, 3))
print(arr)
print(np.max(arr), np.min(arr))
plt.hist(arr, bins=100)
plt.show()
ndarray 정렬
NumPy 배열 정렬은 np.sort() 함수를 사용하여 수행된다.
이 함수는 배열의 복사본을 생성하여 정렬된 배열을 반환하며, 기본적으로 오름차순으로 정렬된다.
- 1차원 배열
arr = np.random.randint(1, 11, 10)
# np.sort(arr) : 정렬된 ndarray를 '반환', 원본 배열에 영향을 주지 않음.
arr = np.sort(arr)
np.sort(arr)[::-1] # 내림차순 정렬
- 2차원 배열
각 행(row) 또는 열(column)을 기준으로 정렬할 수 있다.
기본적으로 각 행을 기준으로 정렬이 수행된다.
* 특정 축(axis)을 기준으로 정렬할 수 있으며, 축 0은 열(Column)을 기준으로, 축 1은 행(row)을 기준으로 정렬한다.
arr = np.random.randint(10, size=(3, 4))
np.sort(arr) # axis 기본값 = 1
print(np.sort(arr, axis=0)) # 행 방향 정렬 (같은 열 안에서 정렬)
print(np.sort(arr, axis=1)) # 열 방향 정렬 (같은 행 안에서 정렬)
print(np.sort(arr, axis=None)) # axis-None 축 무시 (행/열 구분없이 모든 값 정렬)
print(np.sort(arr, axis=None).shape)
인덱스를 반환하는 정렬 (argsort)
👉🏻 np.argsort()
배열의 값을 정렬했을 때, 각 값의 원래 인덱스를 반환
정렬할 때 어떤 순서로 값을 배치해야 하는지 알려주는 인덱스를 반환
배열의 값을 정렬한 후, 정렬된 순서에 해당하는 인덱스를 반환
# 1차원 배열에서 argsort 사용
arr = np.array([100, 400, 200, 300])
print(np.sort(arr)) # [100 200 300 400]
print(np.argsort(arr)) # [0 2 3 1]# 2차원 배열에서 argsort 사용
arr = np.array([[2025, 7, 15], [14, 41, 30]])
print(np.argsort(arr)) # axis 기본값 = 1
print(np.argsort(arr, axis=1)) # 열 방향 정렬의 순서 (같은 행 안에서 정렬)
print(np.argsort(arr, axis=0)) # 행 방향 정렬의 순서 (같은 열 안에서 정렬)
ndarray 병합 및 분할
- ndarray 요소 추가 및 삭제
ndarray는 고정 길이 배열이다 == 크기 변경이 불가하다 == 요소를 추가할 수 있다
# np.append(원본배열, 삽입할 요소): 요소를 추가한 새로운 배열을 반환
# np.insert(원본배열, 삽입할 위치 인덱스, 삽입할 요소): 요소를 추가한 새로운 배열을 반환
arr = np.array([10, 20, 30])
arr1 = np.append(arr, 40)
arr2 = np.insert(arr, 1, 999)
print(arr) # [10 20 30]
print(arr1) # [10 20 30 40]
print(arr2) # [ 10 999 20 30]
print(arr2 is arr) # False# 2차원 배열에서 insert()
arr2d = np.arange(1, 13).reshape(3, 4)
print(arr2d)
# np.append(arr2d, 100) # 차원이 제거되면서 요소가 뒤에 붙음
print(np.insert(arr2d, 1, 100)) # axis=None: 1차원 배열로 변환 후 요소 삽입
# 파라미터 -> 원본배열, 삽입할 위치 인덱스, 삽입할 요소, axis (0=행 기준 / 1=열 기준)
print(np.insert(arr2d, 1, 100, axis=0))
print(np.insert(arr2d, 1, 100, axis=1))
print(np.insert(arr2d, 1, 100, axis=1))
print(np.insert(arr2d, 1, [100], axis=1))
print(np.insert(arr2d, 1, [100, 200, 300], axis=1))
# print(np.insert(arr2d, 1, [100, 200, 300], axis=0)) # 삽입하려는 값의 형태가 기존 shape에 맞지 않으면 error 발생
print(np.insert(arr2d, 1, [100, 200, 300, 400], axis=0))# np.delete(원본배열, 삭제할 요소의 위치 인덱스): 요소를 삭제한 새로운 배열을 반환
arr = np.arange(1, 15)
arr1 = np.delete(arr, 7)
print(arr)
print(arr1)
arr_2d = np.arange(1, 13).reshape(3, 4)
print(arr_2d)
print(np.delete(arr2d, 1)) # axis=None: 1차원 배열로 변환 후 요소 삭제
print(np.delete(arr2d, 1, axis=0))
print(np.delete(arr2d, 1, axis=1))
- ndarray 병합
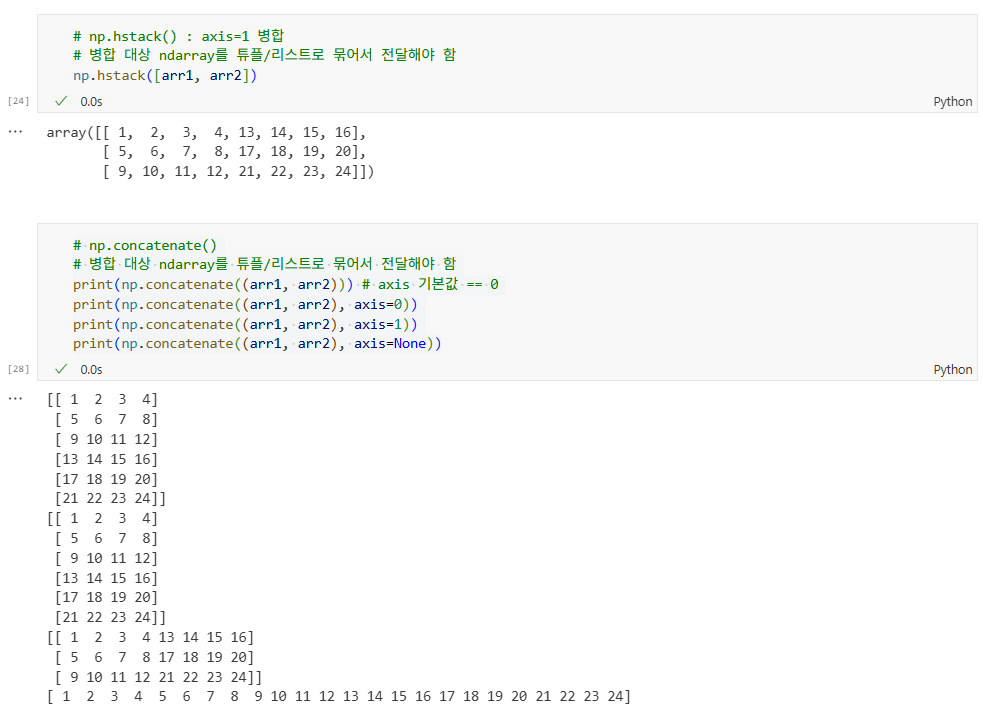
np.append()
np.vstack() : 수직으로 배열을 병합하는 함수로, 배열을 행(row) 기준으로 쌓는다. 여러 배열을 위아래로 병합할 수 있다.
np.hstack() : 수평으로 배열을 병합하는 함수로, 배열을 열(column) 기준으로 쌓는다. 여러 배열을 좌우로 병합할 수 있다.
np.concatenate() : 주어진 축(axis)을 기준으로 배열을 병합하는 함수이다. 기본적으로 축 0을 기준으로 병합한다.
arr1 = np.arange(1, 13).reshape(3, 4)
arr2 = np.arange(13, 25).reshape(3, 4)
print(np.append(arr, arr2)) # axis=None
print(np.append(arr1, arr2, axis=0))
print(np.append(arr1, arr2, axis=1))
# np.vstack() : axis=0 병합
# 병합 대상 ndarray를 튜플/리스트로 묶어서 전달해야 함
np.vstack([arr1, arr2])
# np.hstack() : axis=1 병합
# 병합 대상 ndarray를 튜플/리스트로 묶어서 전달해야 함
np.hstack([arr1, arr2])
# np.concatenate()
# 병합 대상 ndarray를 튜플/리스트로 묶어서 전달해야 함
print(np.concatenate((arr1, arr2))) # axis 기본값 == 0
print(np.concatenate((arr1, arr2), axis=0))
print(np.concatenate((arr1, arr2), axis=1))
print(np.concatenate((arr1, arr2), axis=None))
- ndarray 분할
👉🏻 split()
arr = np.concatenate((arr1, arr2))
print(arr.shape)
# np.split(원본 배열, 분할할 개수, axis)
print(np.split(arr, 2)) # axis 기본 값 == 0
print(np.split(arr, 2, axis=0))
print(np.split(arr, 2, axis=1))
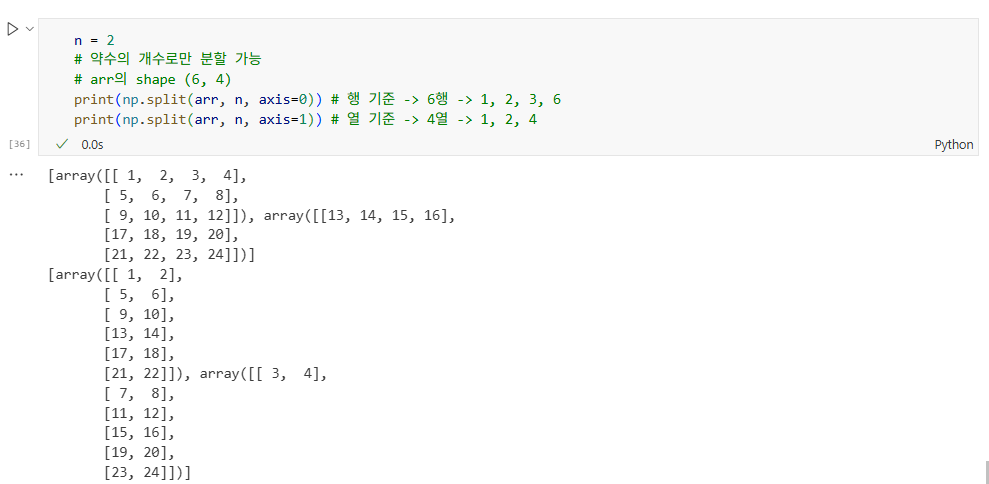
n = 2
# 약수의 개수로만 분할 가능
# arr의 shape (6, 4)
print(np.split(arr, n, axis=0)) # 행 기준 -> 6행 -> 1, 2, 3, 6
print(np.split(arr, n, axis=1)) # 열 기준 -> 4열 -> 1, 2, 4
ndarray 형태 변경
- reshape() : 요소의 개수가 맞는 shape으로 변경 가능
arr = np.arange(12)
print(arr.ndim, arr.shape) # 1 (12,)
arr = arr.reshape(2, 2, 3)
print(arr.ndim, arr.shape)
print(arr)
# 3 (2, 2, 3)
# [[[ 0 1 2]
# [ 3 4 5]]
#
# [[ 6 7 8]
# [ 9 10 11]]]
# reshape(-1): 1차원 처리
arr = arr.reshape(-1)
print(arr) # [ 0 1 2 3 4 5 6 7 8 9 10 11]
# reshape(a, b) -> a or b 하나가 -1 : -1인 축은 자동 계산
arr = arr.reshape(4, -1)
arr = arr.reshape(-1, 4)
print(arr)
# [[ 0 1 2 3]
# [ 4 5 6 7]
# [ 8 9 10 11]]
- np.ravel() : 1차원 변환
arr = np.ravel(arr)
print(arr) # [ 0 1 2 3 4 5 6 7 8 9 10 11]
- np.expand_dims() : 차원 추가
arr_1d = np.arange(10)
print(arr_1d.shape, arr_1d)
print(np.expand_dims(arr_1d, axis=0))
print(np.expand_dims(arr_1d, axis=0).shape)
print(np.expand_dims(arr_1d, axis=1))
print(np.expand_dims(arr_1d, axis=1).shape)
- np.squeeze() : 차원의 값(=해당 차원의 요소 개수)이 1일 때, 차원 제거
arr = np.array([[1, 2]])
print(arr.shape) # (1, 2)
arr2 = np.squeeze(arr)
arr2 = np.squeeze(arr, axis=0)
# arr2 = np.squeeze(arr, axis=1) # ValueError (값이 있는 걸 제거하려고 하니까)
print(arr2.shape) # (2,)'데이터 분석과 머신러닝, 딥러닝 > 데이터 분석' 카테고리의 다른 글
| 3.2.5 [데이터 분석] 데이터 시각화 (1) | 2025.07.17 |
|---|---|
| 3.2.4 [데이터 분석] 데이터 전처리 (0) | 2025.07.17 |
| 3.2.3 [데이터 분석] Pandas (13) | 2025.07.16 |
| 3.2.1 [데이터 분석] 개요 (2) | 2025.07.14 |


