
Developer's Development
3.2.9 [머신러닝] 결정 트리 본문
결정 트리 (Decision Tree)
지도 학습 알고리즘으로, 데이터를 조건에 따라 분할하여 예측하는 데 사용된다. 데이터가 분할될 때마다 불확실성이 줄어들도록 설계되어 있으며, 분류와 회귀 문제 모두에 효과적으로 적용할 수 있다.
👉🏻 결정 트리 구조
- 루트 노드 : 시작점 (가장 먼저 분할하는 조건)
- 규칙 노드 : 조건이나 어떠한 규칙에 의해서 분할하는 것
- 리프 노드 : 마지막 결정 조건에 맞춰서 마지막에 남은 것으로 끝 노드에 해당 (더이상 조건에 맞춰서 규칙 노드를 적용할 수 없는, 더이상 쪼갤 수 없는 것을 리프 노드라고 한다. 맨 마지막에 남는 것은 항상 리프 노드가 된다. 즉, 최종 결정된 값을 의미한다.)
👉🏻 결정 트리 특징
- 해석 용이성 : 결정 트리는 각 분할 과정을 쉽게 시각화할 수 있어, 해석과 설명이 용이하다.
- 비모수적 방법 : 데이터의 분포에 대한 사전 가정이 없고, 다양한 분류 문제에 적용 가능하다.
- 과적합 위험 : 트리 깊이가 너무 깊으면 과적합될 수 있어, 적절한 가지치기(pruning)가 필요하다.
- 결정 트리 학습과 시각화
👉🏻 학습 과정
결정 트리는 데이터의 특징(feature)을 기준으로 분할을 반복하며 학습한다.
각 분할은 질문 형태로 표현되며, 데이터의 불확실성을 최소화하도록 설계한다.
1. 루트 노드 :
- 트리의 시작점으로, 전체 데이터가 포함된 상태이다.
2. 분할 :
- 특징 값에 따라 데이터를 분리하여 자식 노드를 생성한다.
- 분할 기준은 정보 이득이나 지니 불순도를 최대화하도록 설정한다.
3. 리프 노드 :
- 더 이상 분할할 필요가 없거나, 규제 조건에 도달했을 때 생성된다.
- 리프 노드에는 클래스 레이블(분류) 또는 예측 값(회귀)이 할당된다.
클래스 확률 추정
결정 트리는 분류 문제에서 각 클래스에 속할 확률을 추정할 수 있다. 리프 노드에서 데이터의 비율을 기반으로 확률을 계산한다.
CART 훈련 알고리즘
CART(Classification And Regression Tree) 알고리즘은 결정 트리를 학습시키는 대표적인 방법이다.
CART는 트리의 분할 기준을 지니 불순도(Gini Impurity) 또는 MSE(Mean Squared Error)로 설정한다.
* 지니 지수 : 순수하게 찾고자 하는 것 외에 다른 것(=불순물)이 얼마나 끼어있는지 눈으로 확인할 수 있는 계수
정보 이득(Information Gain)과 엔트로피
엔트로피는 데이터의 불확실성을 측정하는 지표로, 분류 문제에서 얼마나 혼합된 데이터를 가지고 있는지를 나타낸다.
엔트로피가 높을수록 데이터가 더 혼란스럽고, 엔트로피가 낮을수록 데이터가 더 잘 정돈된 상태다.
👉🏻 엔트로피와 지니 불순도의 차이
엔트로피는 더 복잡한 계산을 요구하지만, 정보 이득을 기반으로 분할의 효율성을 높인다.
지니 불순도는 계산이 간단하며 CART 알고리즘에서 기본으로 사용된다.
👉🏻 정보 이득 (Information Gain)
데이터를 특정 속성(특징)에 따라 분할했을 때, 불확실성이 얼마나 줄어드는지를 측정하는 지표다.
높은 정보 이득을 가진 속성을 선택하면 데이터의 엔트로피를 크게 줄일 수 있다.
규제 매개변수
결정 트리는 과적합(Overfiting)을 방지하기 위해 다양한 규제 매개변수를 제공한다.
대표적인 매개변수는 다음과 같다.
1. 최대 깊이 (max_depth)
- 트리의 최대 깊이를 제한한다.
- 깊이를 줄이면 과적합을 방지할 수 있다.
2. 최소 샘풀 수 (min_samples_split)
- 노드를 분할하기 위한 최소 샘플 수를 지정한다.
3. 최소 리프 샘플 수 (min_samples_leaf)
- 리프 노드에 있어야 할 최소 샘플 수를 설정한다.
4. 최대 특징 수 (max_features)
- 각 분할에서 사용할 최대 특징 개수를 지정한다.
회귀
결정 트리는 회귀 문제에도 사용된다. 회귀 문제에서는 각 리프 노드에 평균값을 예측 값으로 할당한다.
장점 : 비선형 데이터에 강하고, 데이터 전처리가 간단하다.
결정 트리의 불안정성
결정 트리는 데이터에 민감하여 불안정성이 높을 수 있다. 작은 데이터 변화가 트리의 구조에 큰 영향을 줄 수 있다. 이를 해결하기 위해 앙상블 학습(랜덤 포레스트, 부스팅 등)을 사용하는 것이 일반적이다.
[참고] 과적합 방지 (가지치기)
과적합은 모델이 학습 데이터에 지나치게 맞춰져, 새로운 데이터에 대한 일반화 성능이 떨어지는 문제를 말한다. 결정 트리의 경우, 트리가 너무 깊어져 학습 데이터의 세부 사항(노이즈까지)을 지나치게 학습하면 과적합이 발생할 수 있다.
- 가지치기의 개념
가치치기(Pruning)은 결정 트리의 과적합을 방지하기 위해 불필요하거나 과도한 분기를 제거하는 과정이다.
가지치기는 트리의 복잡도를 줄여 모델의 일반화 성능을 향상시킨다.
- 가지치기의 장점
모델의 복잡도를 줄이고, 학습 데이터의 노이즈를 과도하게 학습하는 것을 방지한다.
과적합을 완화하여 새로운 데이터에 대한 일반화 성능을 향상시킨다.
트리의 크기를 줄여 계산 비용을 감소시킨다.
- 가지치기와 성능 간의 균형
가지치기는 과적합을 방지하지만, 너무 많은 가지치기는 과소적합(Underfitting)을 초래할 수 있다.
적절한 가지치기를 위해 검증 데이터를 사용하거나 교차 검증을 통해 최적의 트리 크기를 선택하는 것이 중요하다.
결정트리 - 분류 (DecisionTreeClassifier)
wine 이진 분류
와인 품질 데이터셋을 가공 > 레드/화이트 와인 이진분류 데이터셋
- 0: 레드 와인
- 1: 화이트 와인
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as snswine_df = pd.read_csv('./data/wine_simple.csv')
wine_df.describe() # class 컬럼이 분류 대상
# 데이터 분리 및 스케일링
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import StandardScaler
X = wine_df.drop('class', axis=1)
y = wine_df['class']
X_train, X_test, y_train, y_test = train_test_split(X, y, random_state=0)
print(X_train.shape, X_test.shape)
scaler = StandardScaler()
X_train = scaler.fit_transform(X_train)
X_test = scaler.transform(X_test)
# 모델 학습 및 평가
from sklearn.tree import DecisionTreeClassifier
# random_state를 설정하지 않으면, 실행할 때마다 score 값이 계속 달라짐
# max_depth는 일종의 가지치기
dt_clf = DecisionTreeClassifier(random_state=0, max_depth=3)
dt_clf.fit(X_train, y_train)
dt_clf.score(X_train, y_train), dt_clf.score(X_test, y_test)
# (0.8433908045977011, 0.8584615384615385)
# 시각화
from sklearn.tree import plot_tree
plt.figure(figsize=(20, 10))
plot_tree(dt_clf)
plt.savefig('wine_simple.png')
plt.show()
from sklearn.tree import plot_tree
plt.figure(figsize=(20, 10))
plot_tree(
dt_clf,
filled=True,
feature_names=X.columns,
class_names=['red wine', 'white wine'],
# max_depth=3 # plot_tree에서 max_depth는 보여지는 것에서 제한
)
plt.savefig('wine_simple.png')
plt.show()
"""
sugar <= -0.284 : DecisionTreeClassifier이 정한 분할 기준
gini = 0.373 : 지니계수(지니 불순도)
samples = 4872 : 현재 노드의 전체 샘플수
value = [1207, 3665]: 클래스별 샘풀 개수(0번 클래스 1207, 1번 클래스가 3665)
class = whilte wine : 현재 노드의 클래스(= value가 많은 클래스)
"""
# 지니 불순도 직접 계산
1 - ((12 / 510)**2 + (498 / 510)**2)
# 특성 중요도
# [alchol, sugar, pH] 순서
dt_clf.feature_importances_ # array([0.11483515, 0.87892904, 0.00623581]) /스케일링 전후 모두 sugar의 중요도가 제일 높음 (실제는 alchol인데)
- iris 다중 분류
from sklearn.datasets import load_iris
from sklearn.model_selection import train_test_split
from sklearn.tree import DecisionTreeClassifier
from sklearn.tree import plot_tree
# 데이터 로드 및 분리
iris = load_iris()
X_train, X_test, y_train, y_test = train_test_split(iris.data, iris.target, random_state=0)
# 모델 학습 및 평가
dt_clf = DecisionTreeClassifier(random_state=0, max_depth=3)
dt_clf.fit(X_train, y_train)
dt_clf.score(X_train, y_train), dt_clf.score(X_test, y_test)
# 트리모델 시각화
plt.figure(figsize=(20, 10))
plot_tree(
dt_clf,
filled=True,
feature_names=iris.feature_names,
class_names=iris.target_names
)
plt.show()
# 지니불순도 감소에 기여한만큼 중요도가 높아짐
print(iris.feature_names)
dt_clf.feature_importances_
# ['sepal length (cm)', 'sepal width (cm)', 'petal length (cm)', 'petal width (cm)']
# array([0. , 0. , 0.42232109, 0.57767891])
결정트리 - 회귀 (DecisionTreeRegressor)
from sklearn.datasets import fetch_california_housing
from sklearn.tree import DecisionTreeRegressor
from sklearn.metrics import mean_squared_error, r2_score
housing_data = fetch_california_housing()
X_train, X_test, y_train, y_test = train_test_split(housing_data.data, housing_data.target, random_state=0)
dt_reg = DecisionTreeRegressor(random_state=0, max_depth=5)
# 학습
dt_reg.fit(X_train, y_train)
# 예측
pred_train = dt_reg.predict(X_train)
pred_test = dt_reg.predict(X_test)
# 평가
mse_train = mean_squared_error(y_train, pred_train)
r2_train = r2_score(y_train, pred_train)
mse_test = mean_squared_error(y_test, pred_test)
r2_test = r2_score(y_test, pred_test)
# 평가 지표 출력
print(f"훈련 데이터에 대한 평가: mse {mse_train}, r2 {r2_train}")
print(f"테스트 데이터에 대한 평가: mse {mse_test}, r2 {r2_test}")
# 시각화
plt.figure(figsize=(20, 10))
plot_tree(
dt_reg,
filled=True,
feature_names=housing_data.feature_names
)
plt.show()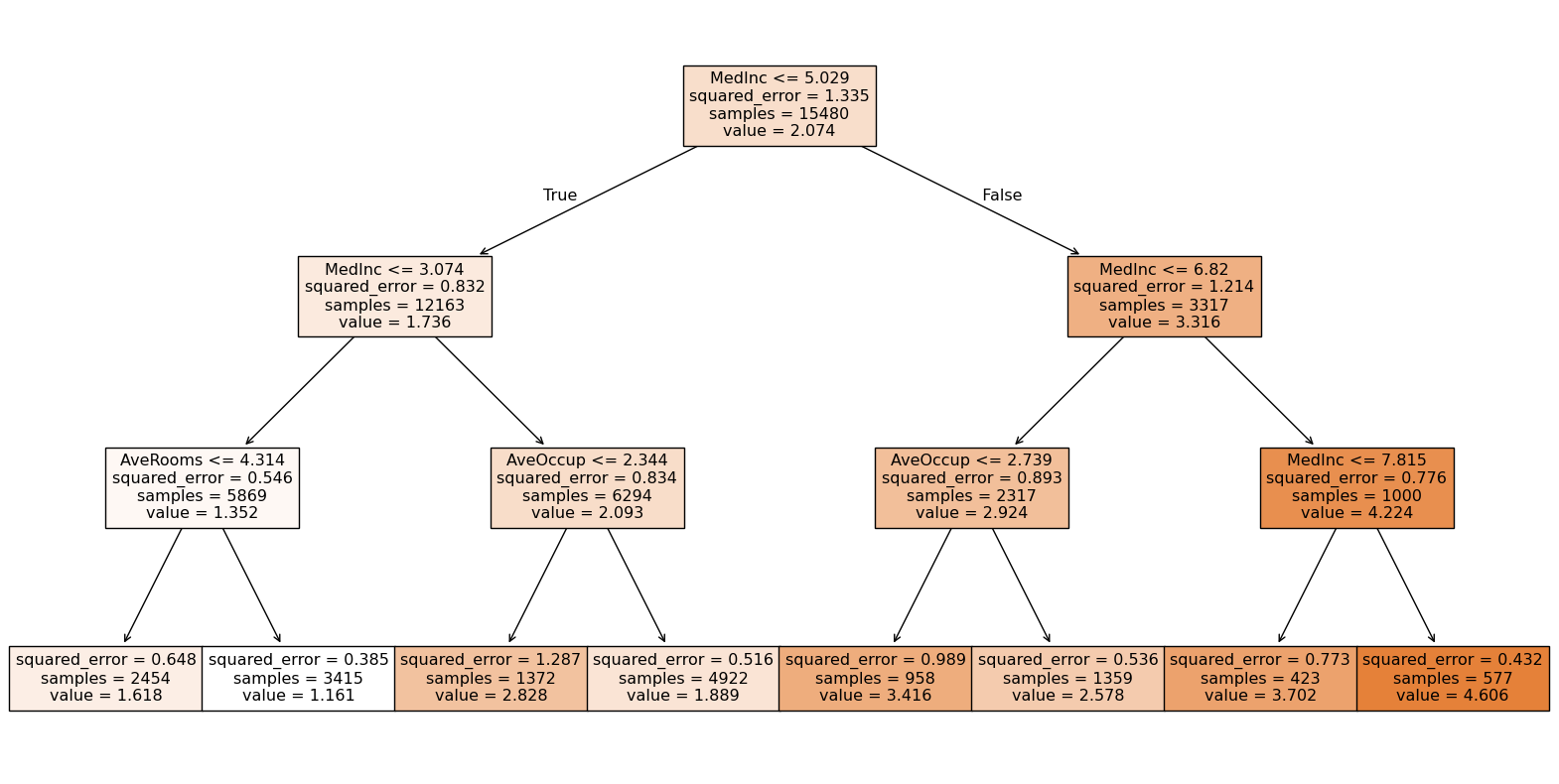
# 특성 중요도
dt_reg.feature_importances_
# 특성 중요도 시각화
sns.barplot(
x=dt_reg.feature_importances_,
y=housing_data.feature_names,
hue=housing_data.feature_names
)
plt.show()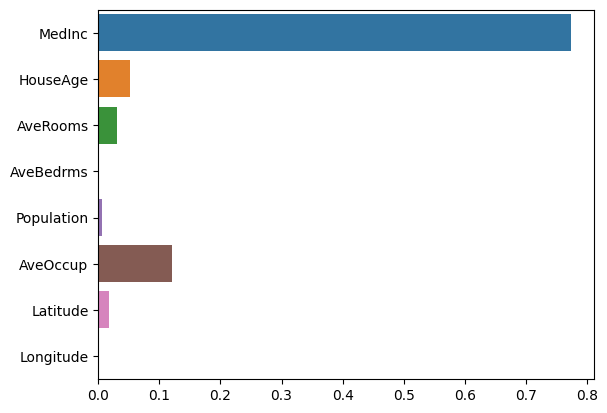
'데이터 분석과 머신러닝, 딥러닝 > 머신러닝' 카테고리의 다른 글
| 3.2.11 [머신러닝] 앙상블 (2) | 2025.08.03 |
|---|---|
| 3.2.10 [머신러닝] 서포트 벡터 머신 (0) | 2025.07.24 |
| 3.2.8 [머신러닝] 분류 (1) | 2025.07.24 |
| 3.2.7 [머신러닝] 회귀 (5) | 2025.07.21 |
| 3.2.6 [머신러닝] 개요 (9) | 2025.07.18 |



