
Developer's Development
3.2.18 [딥러닝] 인공신경망(2) 본문
손실 함수 (Loss function)
신경망의 학습에서 예측값과 실제값의 차이를 측정하는 함수이다.
모델이 학습하는 방향을 결정하는 중요한 요소이며, 모델이 더 나은 예측을 할 수 있도록 가중치를 조정하는 기준이 된다.
손실 함수는 문제 유형에 따라 적절한 함수를 선택해야 하며, 대표적으로 다음과 같이 구분된다.
- 회귀 문제(Regression) : 평균 제곱 오차(MSE), 평균 절대 오차(MAE), Huber 손실(Huber Loss)
- 분류 문제(Classification) : 교차 엔트로피 손실(CEE), 음성 로그 가능도(NLL, Negative Log Likelihood), Hinge Loss(SVM)
- 강화 학습(Reinforcement Learning) : 정책 그래디언트 손실(Policy Gradient Loss), Huber 손실(Huber Loss)
- 평균 제곱 오차 (Mean Squared Error, MSE)
회귀 문제에서 주로 사용하는 손실 함수로, 실제 값과 예측값의 차이를 제곱하여 평균을 낸 값이다.
오차가 클수록 더 크게 반영되므로 이상치에 민감하다.
- 평균 절대 오차 (Mean Absolute Error, MAE)
실제값과 예측값의 차이의 절대값을 평균 낸 값이다.
MSE보다 이상치에 덜 민감하며, 전반적인 오차 크기를 측정할 때 유용하다.
- Huber 손실
MSE와 MAE의 장점을 결합한 손실 함수이다.
작은 오차에는 MSE처럼 작용하지만, 특정 임계값(delta) 이상에서는 MAE처럼 작용하여 이상치에 덜 민감하다.
import numpy as np
def mean_squared_error(y_true, y_pred):
return np.mean((y_true - y_pred) ** 2)
def mean_absolute_error(y_true, y_pred):
return np.mean(np.abs(y_true - y_pred))
y_true = np.array([1.0, 2.0, 3.0, 4.0, 5.0])
y_pred = np.array([1.2, 1.8, 3.1, 3.9, 4.8])
y_true = np.append(y_true, [50.0, 60.0])
y_pred = np.append(y_pred, [10.0, 5.0])
mse = mean_squared_error(y_true, y_pred)
mae = mean_absolute_error(y_true, y_pred)
print("MSE: ", mse) # MSE: 660.7342857142858
print("MAE: ", mae) # MAE: 13.685714285714285 /이상치에 민감def huber_loss(y_true, y_pred, delta=1.0):
error = y_true - y_pred
is_small_error = np.abs(error) <= delta
squared_loss = 0.5 * (error ** 2)
linear_loss = delta * (np.abs(error) - 0.5 * delta)
return np.mean(np.where(is_small_error, squared_loss, linear_loss))
huber_loss(y_true, y_pred) # np.float64(13.438571428571427) /MSE보다 안정적, MAE보다 낮음
- 교차 엔트로피 오차 (Cross Entropy Error, CEE)
분류 문제에서 주로 사용하는 손실함수이다.
실제값이 특정 클래스에 속할 확률과 예측 확률을 비교하여 손실을 계산한다.
👉🏻 Softmax와 교차 엔트로피
: 신경망의 출력층에서 Softmax 함수를 사용하여 확률 분포를 만든 후, CEE를 적용하여 모델 성능을 평가한다.
- 미니배치 학습 (Mini-batch Learning)
전체 데이터셋이 아닌 일부 데이터를 무작위로 선택하여 학습하는 방법이다.
전체 데이터를 한 번에 학습하는 것보다 계산량이 적고, SGD(확률적 경사 하강법)보다 안정적이다.
👉🏻 배치 크기의 영향
- 작은 배치 크기 : 빠르게 학습하지만 변동성이 큼
- 큰 배치 크기 : 안정적이지만 계산 비용이 증
- 신경망 모델에서 손실 함수 활용
import numpy as np
import matplotlib.pyplot as plt
from sklearn.datasets import make_classification
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import StandardScaler
# 데이터 생성
X, y = make_classification(
n_samples = 1000,
n_features = 20,
n_informative = 15,
n_redundant = 5,
n_classes = 2,
random_state = 42
)
# 정규화
scaler = StandardScaler()
X = scaler.fit_transform(X)
X_train, X_test, y_train, y_test = train_test_split(X, y, random_state=42)
# 전처리(원-핫인코딩)
# 모델 출력값과 비교 가능한 형태로 레이블을 백터화
def one_hot(labels, num_classes):
return np.eye(num_classes)[labels]
y_train_oh = one_hot(y_train, 2)
y_test_oh = one_hot(y_test, 2)
# 모델 파라미터 초기화
np.random.seed(42)
input_dim = X_train.shape[1]
hidden_dim = 32
ouput_dim = 2
# 2층 신경망 구조 (입력 -> 은닉층(ReLU) -> 출력층(Softmax))
# 가중치 초기화: 정규분포에서 랜덤 생성
W1 = np.random.randn(input_dim, hidden_dim)
b1 = np.zeros((1, hidden_dim))
W2 = np.random.randn(hidden_dim, ouput_dim)
b2 = np.zeros((1, ouput_dim))
# 활성화 함수, 손실 함수 정의
def relu(z):
return np.maximum(0, z) # 은닉층에서 쓰임(음수는 죽이고 양수는 그대로)
def softmax(z):
exp_z = np.ezp(z - np.max(z, axis=1, keepdims=True))
return exp_z / np.sum(exp_z, axis=1, keepdims=True) # 출력층에서 쓰임 -> 확률처럼 해석
def cross_entropy_loss(probs, labels):
m = labels.shape[0]
log_liklihood = -np.log(probs + 1e-8) * labels
loss = np.sum(log_liklihood) / m
return loss # 예측한 확률이 정답과 얼마나 가까운지를 수치로 나타냄
# 학습
learning_rate = 0.01
epochs = 50
train_losses = []
test_losses = []
for epoch in range(epochs):
# Forward (순전파)
# 순방향 계산으로 예측값 생성, 그 예측과 정답을 비교해 손실(loss) 계산
Z1 = np.dot(X_train, W1) + b1
R1 = relu(Z1)
Z2 = np.dot(R1, W2) + b2
probs = softmax(Z2)
loss = cross_entropy_loss(probs, y_train_oh)
# Backpropagation (역전파)
# 예측 오차를 기준으로 가중치 업데이트를 위한 기울기 계산
m = X_train.shape[0]
dZ2 = (probs - y_train_oh) / m
dW2 = np.dot(R1.T, dZ2)
db2 = np.sum(dZ2, axis=0, keepdims=True)
dR1 = np.dot(dZ2, W2.T)
dZ1 = dR1 * (Z1 > 0)
dW1 = np.dot(X_train.T, dZ1)
db1 = np.sum(dZ1, axis=0, keepdims=True)
# (모델) 파라미터 업데이트
# 가중치를 조금씩 조정하며, 손실을 줄여나감
W1 -= learning_rate * dW1
b1 -= learning_rate * db1
W2 -= learning_rate * dW2
b2 -= learning_rate * db2
train_losses.append(loss)
# 테스트 데이터로 손실 확인
Z1_test = np.dot(X_test, W1) + b1
R1_test = relu(Z1_test)
Z2_test = np.dot(R1_test, W2) + b2
probs_test = softmax(Z2_test)
loss_test = cross_entropy_loss(probs_test, y_test_oh)
test_losses.append(loss_test)
# 학습 결과 손실 출력
# 10 에폭마다 현재 학습과 테스트 손실을 확인
if (epoch + 1) % 10 == 0:
print(f"Epoch {epoch + 1} | 학습 손실: {loss:.4f}, 테스트 손실: {loss_test:.4f}")
"""
Epoch 10 | 학습 손실: 4.3756, 테스트 손실: 4.6673
Epoch 20 | 학습 손실: 3.9200, 테스트 손실: 4.2563
Epoch 30 | 학습 손실: 3.5888, 테스트 손실: 3.9074
Epoch 40 | 학습 손실: 3.3203, 테스트 손실: 3.6308
Epoch 50 | 학습 손실: 3.0936, 테스트 손실: 3.3961
"""# 학습 곡선 시각화
plt.plot(range(epochs), train_losses, label="train loss")
plt.plot(range(epochs), test_losses, label="test loss")
plt.xlabel('epoch')
plt.ylabel('loss')
plt.legend()
plt.show()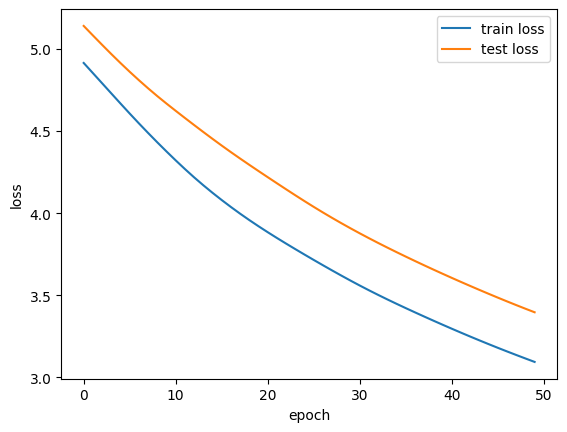
- 기본 손실 함수 vs 커스텀 손실 함수
from sklearn.datasets import make_regression
# 데이터 생성
X, y = make_regression(
n_samples=1000,
n_features=10,
noise=50,
random_state=42
)
# 전처리
scaler_X = StandardScaler()
scaler_y = StandardScaler()
X = scaler_X.fit_transform(X)
y = scaler_y.fit_transform(y.reshape(-1, 1)).flatten()
X_train, X_test, y_train, y_test = train_test_split(X, y, random_state=42)
# 예측 함수
def predict(X, w, b):
return np.dot(X, w) + b
# 손실 함수
def mse_loss(y_pred, y_true):
return np.mean((y_pred - y_true) ** 2)
# l2 정규화 적용
def my_loss(y_pred, y_true, w, lamda_reg=1.0):
mse = mse_loss(y_pred, y_true)
l2_reg = np.sum(w ** 2)
return mse + (lamda_reg + l2_reg
def train_model(X_train, y_train, X_test, y_test, loss_fn, epochs=50, learning_rate=0.1, use_custom=False):
np.random.seed(42)
n_features = X_train.shape[1]
W = np.random.randn(n_features)
b = 0.0
for epoch in range(epochs):
y_pred_train = predict(X_train, X, b)
y_pred_test = predict(X_test, W, b)
train_loss = loss_fn(y_pred_train, y_train, W) \
if use_custom else loss_fn(y_pred_train, y_train)
test_loss = loss_fn(y_pred_test, y_test, W) \
if use_custom else loss_fn(y_pred_test, y_test)
d_loss = 2 * (y_pred_train - y_train) / X_train.shape[0]
grad_w = np.dot(X_train.T, d_loss)
grad_b = np.sum(d_loss)
if use_custom:
grad_w += 2 * 1.0 * W
W -= learning_rate * grad_w
b -= learning_rate * grad_b
if (epoch + 1) % 10 == 0:
print(f"Epoch {epoch+1} | 학습 손실: {train_loss:.4f}, 테스트 손실: {test_loss:.4f}")
train_model(X_train, y_train, X_test, y_test, mse_loss)
train_model(X_train, y_train, X_test, y_test, my_loss, use_custom=True)
- 손실 함수 선택이 모델 성능에 미치는 영향
🐿️ 손실 함수도 모델 성능에 영향을 준다. 언제나 MSE를 쓴다고 좋은 것도 아님!
# 위 코드들은 생략
results = {}
for name, loss_fn in zip(["MSE", "MAE", "Huber"], [mse_loss, mae_loss, huber_loss]):
W, b, losses = train_regression(X_train, y_train, loss_fn)
results[name] = {"losses": losses}
pred_test = predict(X_test, W, b)
test_loss = mse_loss(pred_test, y_test)
print(f'{name} Loss: {test_loss:.4f}')
"""
MSE Loss: 0.4267
MAE Loss: 4.5130
Huber Loss: 2.8584
"""
# 시각화
for name, value in results.items():
plt.plot(value["losses"], label=name)
plt.xlabel('epoch')
plt.ylabel('train loss')
plt.legend()
plt.show()
수치 미분 (Numerical Differentiation)
함수의 변화량을 근사적으로 구하는 방법이다.
실제 미분값을 구하는 것이 어렵거나 불가능한 경우 사용된다.
- 수치 미분의 한계
수치 미분은 근사값을 구하는 방법이므로, 정확한 해석적 미분값과 오차가 발생할 수 있다.
미분을 구하는 데 사용되는 h 값의 선택이 중요하다.
- h 값이 너무 크면 근사 오차가 증가한다.
- h 값이 너무 작으면 부동소수점 연산 오차가 커질 수 있다.
▶️ 신경망 학습에서는 이러한 수치 미분 대신 자동 미분(Autograd) 기법이 자주 사용된다.
- 편미분 (Partial Derivative)
다변수 함수에서 특정 변수에 대해 미분하는 것이다.
- 편미분과 기울기 벡터(Gradient Vector)
다변수 함수에 대해, 특정 변수에 대한 편미분을 각각 계산할 수 있다. 이를 벡터 형태로 나타낸 것을 기울기 벡터라고 한다.
기울기 벡터는 ㅎ마수의 변화 방향을 나타내며, 경사 하강법에서 중요한 역할을 한다.
- 1차원 함수의 수치 미분
import numpy as np
def f(x):
return x ** 2
# 해석적 미분
def analytical_d(x):
return 2 * x
# 전진 차분법
def num_d_forward(f, x, h=1e-5):
return (f(x + h) - f(x)) / h
# 후진 차분법
def num_d_backward(f, x, h=1e-5):
return (f(x) - f(x - h)) / h
# 중앙 차분법
def num_d_central(f, x, h=1e-5):
return (f(x + h) - f(x - h)) / (2 * h)
x = 3.0
print(analytical_d(x))
print(num_d_forward(f, x))
print(num_d_backward(f, x))
print(num_d_central(f, x))
"""
6.0
6.000009999951316
5.999990000127297
6.000000000039306
"""
- 다변수 함수의 수치 미분
def f(x, y):
return x ** 2 + y ** 2
# 편미분
def partial_d(f, x, y, var='x', h=1e-5):
if var == 'x':
return (f(x + h, y) - f(x - h, y)) / (2 * h)
else:
return (f(x, y + h) - f(x, y - h)) / (2 * h)
print(partial_d(f, 3.0, 2.0, var='x')) # 6.000000000039306
# 4.000000000026205
def f_multi(x):
return np.sum(x ** 2)
def analytical_gradient(x):
return 2 * x
def num_d_gradient(f, x, h=1e-5):
grad = np.zeros_like(x)
for idx in range(len(x)):
tmp = x[idx]
x[idx] = tmp + h
f_plus = f(x)
x[idx] = tmp - h
f_minus = f(x)
grad[idx] = (f_plus - f_minus) / (2 * h)
x[idx] = tmp
return grad
x = np.array([1.0, 2.0, 3.0])
print(analytical_gradient(x)) # [2. 4. 6.]
print(num_d_gradient(f_multi, x)) # [2. 4. 6.]
- 간단한 신경망의 기울기
def sigmoid(z):
return 1 / (1 + np.exp(-z))
def forward_pass(x, params):
W1, b1, W2, b2 = params
z1 = np.dot(x, W1) + b1
r1 = sigmoid(z1)
z2 = np.dot(r1, W2) + b2
r2 = sigmoid(z2)
return r2
def loss(r2, y):
return 0.5 * np.sum((r2 - y) ** 2)
def get_loss(params, x, y):
r2 = forward_pass(x, params)
return loss(r2, y)
def num_d_gradient_params(f, params, x, y, h=1e-5):
grads = []
for param in params:
grad = np.zeros_like(param)
iter = np.nditer(param, flags=['multi_index'], op_flags=['readwrite'])
while not iter.finished:
idx = iter.multi_index
origin_val = param[idx]
param[idx] = origin_val + h
f_plus = f(params, x, y)
param[idx] = origin_val - h
f_minus = f(params, x, y)
grad[idx] = (f_plus - f_minus) / (2 * h)
param[idx] = origin_val
iter.iternext()
grads.append(grad)
return grads
np.random.seed(0)
input_size = 2
hidden_size = 3
output_size = 1
W1 = np.random.randn(input_size, hidden_size)
b1 = np.random.randn(hidden_size)
W2 = np.random.randn(hidden_size, output_size)
b2 = np.random.randn(output_size)
params = [W1, b1, W2, b2]
X = np.array([0.5, -0.2])
y = np.array([1.0])
num_grads = num_d_gradient_params(get_loss, params, X, y)
for i, grad in enumerate(num_grads):
print(f"{i}번째 파라미터 수치 미분 기울기:\n {grad}")
- h값에 따른 영향
🐿️ 적절한 h값을 선택하는 게 수치 미분에서 중요!
import matplotlib.pyplot as plt
def f(x):
return x ** 2
def analytical_d(x):
return 2 * x
def num_d_central(f, x, h=1e-5):
return (f(x + h) - f(x - h)) / (2 * h)
x = 3.0
h_values = np.logspace(-10, -1, 50)
errors = []
true_d = analytical_d(x)
for h in h_values:
num_d = num_d_central(f, x, h)
error = np.abs(num_d - true_d)
errors.append(error)
plt.figure(figsize=(5, 3))
plt.loglog(h_values, errors, marker='o')
plt.xlabel('h size')
plt.ylabel('error')
plt.grid(True)
plt.show()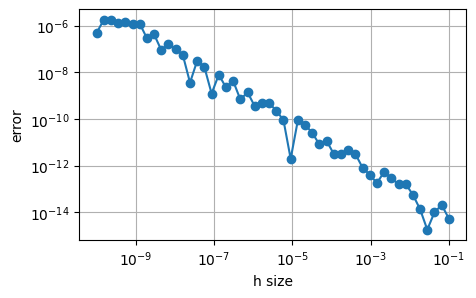
- 자동 미분
import torch
x = torch.tensor(3.0, requires_grad=True)
y = f(x) # x ** 2
y.backward()
print(analytical_d(3.0)) # 6.0
print(x.grad) # tensor(6.)
기울기
- 경사 하강법 (Gradient Descent)
손실 함수읙 기울기를 이용해 최적의 가중치를 찾아가는 방법이다.
특정 매개변수(ex) 가중치, w)에 대해 손실 함수의 기울기를 구하고, 기울기의 반대 방향으로 이동하며 최적점을 찾는다.
학습률(learning rate, lr)이 너무 크면 최적점을 지나칠 수 있고, 너무 작으면 수렴 속도가 느려진다.
- 신경망에서의 기울기
신경망에서는 가중치에 대한 손실 함수의 기울기를 구해야 한다.
수치 미분을 이용한 기울기 계산도 가능하지만, 신경망에서는 수천 개 이상의 매개변수를 다루므로 수치 미분은 비효율적이다.
따라서 신경망 학습에서는 자동 미분(AutoGrad)과 역전파(Backpropagation) 알고리즘을 통해 효율적으로 계산한다.
- 기울기 소실 (Vanishing Gradient) 문제
심층 신경망에서는 역전파 시 기울기가 점차 작아져 초기 층까지 전달되지 않는 문제가 발생할 수 있다.
특히 시그모이드나 하이퍼볼릭 탄젠트(Tanh) 함수 같은 활성화 함수를 사용할 경우, 기울기가 0에 수렴화는 현상이 발생할 가능성이 크다.
👉🏻 해결 방법
- 활성화 함수 변경 : ReLU 나 Leaky ReLU 등의 함수를 사용하면 기울기 소실 문제를 완화할 수 있다.
- 잔차 연결 (Residual Connection) : ResNet 등의 네트워크에서 층을 건너뛰는 연결을 추가하여 기울기의 흐름을 원활하게 만든다.
import numpy as np
import matplotlib.pyplot as plt
def sigmoid(x):
return 1 / (1 + np.exp(-x))
np.random.seed(0)
weights = np.random.randn(10, 10) * 0.01
x = np.random.randn(10, 1)
for i in range(1, 11):
x = sigmoid(np.dot(weights, x))
print(f'{i}번째 총 출력 평균: {np.mean(x)}')
x = np.linspace(-10, 10, 100)
for i in range(1, 6):
x = sigmoid(x)
plt.plot(x, label=f'{i} layer')
plt.xlabel('input')
plt.ylabel('output')
plt.legend()
plt.show()
❗ 활성화 함수 변경
def relu(x):
return np.maximum(0, x)
def sigmoid_grad(x):
return sigmoid(x) * (1 - sigmoid(x))
def relu_grad(x):
return np.where(x > 0, 1, 0)
x = np.linspace(-10, 10, 100)
plt.figure(figsize=(5, 3))
plt.plot(x, sigmoid_grad(x), label="Sigmoid Gradient")
plt.plot(x, relu_grad(x), label="ReLU Gradient")
plt.xlabel("x")
plt.ylabel("gradient")
plt.legend()
plt.show()
❗ 잔차 연결 (Residual Connection) 효과
import torch
import torch.nn as nn
import torch.optim as optim
class SimpleNN(nn.Module):
def __init__(self):
super(SimpleNN, self).__init__()
self.layer1 = nn.Linear(10, 10)
self.layer2 = nn.Linear(10, 10)
def forward(self, x):
return self.layer2(torch.relu(self.layer1(x)))
class ResidualNN(nn.Module):
def __init__(self):
super(ResidualNN, self).__init__()
self.layer = nn.Linear(10, 10)
def forward(self, x):
return x + torch.relu(self.layer(x))
class DeepResidualNN(nn.Module):
def __init__(self):
super(DeepResidualNN, self).__init__()
self.layer1 = nn.Linear(10, 10)
self.layer2 = nn.Linear(10, 10)
self.layer3 = nn.Linear(10, 10)
def forward(self, x):
residual = x
x = torch.relu(self.layer1(x))
x = torch.relu(self.layer2(x))
x = self.layer3(x)
return x + residual
simple_model = SimpleNN()
residual_model = ResidualNN()
X = torch.randn(1, 10)
simple_output = simple_model(X)
residual_output = residual_model(X)
print(f'입력값 - 일반 신경망: { X - simple_output }')
print(f'입력값 - 잔차연결 신경망: { X - residual_output }')# 기울기 변화
# 데이터 생성
X = torch.randn(100, 10)
y = torch.randn(100, 10)
# 모델 생성
sim_model = SimpleNN()
res_model = ResidualNN()
deep_res_model = DeepResidualNN()
# 손실함수, 옵티마이저 생성
criterion = nn.MSELoss()
sim_optim = optim.Adam(sim_model.parameters(), lr=0.01)
res_optim = optim.Adam(res_model.parameters(), lr=0.01)
deep_res_optim = optim.Adam(deep_res_model.parameters(), lr=0.01)
# 학습 루프
epochs = 100
loss_sim_list = []
loss_res_list = []
deep_res_loss_list = []
for epoch in range(epochs):
sim_optim.zero_grad() # 가중치 초기화
sim_output = sim_model(X) # 순전파
sim_loss = criterion(sim_output, y) # 손실 계산
sim_loss.backward() # 역전파
sim_optim.step() # 가중치 업데이트
loss_sim_list.append(sim_loss.item()) # 손실값 append
res_optim.zero_grad() # 가중치 초기화
res_output = res_model(X) # 순전파
res_loss = criterion(res_output, y) # 손실 계산
res_loss.backward() # 역전파
res_optim.step() # 가중치 업데이트
loss_res_list.append(res_loss.item()) # 손실값 append
deep_res_optim.zero_grad() # 가중치 초기화
deep_res_output = deep_res_model(X) # 순전파
deep_res_loss = criterion(deep_res_output, y) # 손실 계산
deep_res_loss.backward() # 역전파
deep_res_optim.step() # 가중치 업데이트
deep_res_loss_list.append(deep_res_loss.item()) # 손실값 append
print(f'일반 신경망 최종 손실값: {loss_sim_list[-1]:.4f}')
print(f'잔차연결 신경망 최종 손실값: {loss_res_list[-1]:.4f}')
print(f'더 깊은 잔차연결 신경망 최종 손실값: {deep_res_loss_list[-1]:.4f}')
"""
일반 신경망 최종 손실값: 0.6731
잔차 연결 신경망 최종 손실값: 1.3816
더 깊은 잔차 연결 신경망 최종 손실값: 0.8079
"""for param in sim_model.parameters():
print(f'일반 신경망 기울기 크기: { param.grad.norm() }')
for param in res_model.parameters():
print(f'잔차연결 신경망 기울기 크기: { param.grad.norm() }')
for param in deep_res_model.parameters():
print(f'더 깊은 잔차연결 신경망 기울기 크기: { param.grad.norm() }')
"""
일반 신경망 기울기 크기: 0.0289564561098814
일반 신경망 기울기 크기: 0.012576238252222538
일반 신경망 기울기 크기: 0.016520220786333084
일반 신경망 기울기 크기: 0.0026862870436161757
잔차연결 신경망 기울기 크기: 0.04687890037894249
잔차연결 신경망 기울기 크기: 0.008709585294127464
더 깊은 잔차연결 신경망 기울기 크기: 0.04064163193106651
더 깊은 잔차연결 신경망 기울기 크기: 0.021119914948940277
더 깊은 잔차연결 신경망 기울기 크기: 0.048183903098106384
더 깊은 잔차연결 신경망 기울기 크기: 0.012578204274177551
더 깊은 잔차연결 신경망 기울기 크기: 0.032614558935165405
더 깊은 잔차연결 신경망 기울기 크기: 0.015601770021021366
"""
- 기울기 폭발 (Exploding Gradient) 문제
기울기가 너무 커져서 가중치가 비정상적으로 갱신되는 현상이다.
RNN(Recurrent Neural Network)과 같이 깊이 네트워크에서 발생하기 쉽다.
👉🏻 해결 방법
- 그래디언트 클리핑 (Gradient Clipping) : 기울기의 크기를 일정 수준 이상 증가하지 않도록 제한한다.
- 가중치 초기화 기법 활용 : Xavier 초기화나 He 초기화를 사용하여 안정적인 학습을 유도한다.
- 다양한 최적화 알고리즘
경사 하강법 외에도 다양한 최적화 기법이 존재하며, 각각의 장단점이 다르다.
- SGD (확률적 경사 하강법) : 랜덤 샘플을 사용하여 학습 속도를 증가
- 모멘텀 (Momentum) : 이전 기울기의 영향을 반영하여 속도를 조절
- RMSProp : 기울기의 변화량을 고려하여 학습률을 조정
- Adam : 모멘텀과 RMSProp을 결합하여 안정적인 학습을 제공
- 기울기 계산의 수치적 안정성
기울기 계산 중 발생하는 수치적 불안정성을 방지하기 위해 정규화 기법을 사용할 수 있다.
- 배치 정규화 (Batch Normalization) : 각 층의 입력을 정규화하여 학습을 안정화한다.
- L2 정규화 : 가중치 값이 과도하게 커지는 것을 방지하여 오버피팅을 줄인다.
'데이터 분석과 머신러닝, 딥러닝 > 딥러닝' 카테고리의 다른 글
| 3.2.21 [딥러닝] 최적 모델 학습 (과적합 해결) (5) | 2025.08.07 |
|---|---|
| 3.2.20 [딥러닝] 최적 모델 학습 (최적화 함수) (2) | 2025.08.06 |
| 3.2.19 [딥러닝] 최적 모델 학습 (오차역전파법) (1) | 2025.08.05 |
| 3.2.16 [딥러닝] 인공신경망 (4) | 2025.08.03 |
| 3.2.15 [딥러닝] 개요 (2) | 2025.08.03 |

