
Developer's Development
3.2.20 [딥러닝] 최적 모델 학습 (최적화 함수) 본문
최적화 함수
딥러닝 모델이 학습하는 과정에서 가장 중요한 요소 중 하나는 최적화 함수이다.
최적화 함수는 손실 함수의 값을 최소화하도록 모델의 가중치를 업데이트하는 역할을 한다.
최적화 함수의 선택은 모델의 학습 속도, 일반화 성능, 수렴 안정성에 큰 영향을 미친다.
대표적인 최적화 함수로 확률적 경사 하강법(SGD), 모맨텀, AdaGrad, RMSprop, Adam 등이 있다.
- 확률적 경사 하강법 (SGD)
경사 하강법은 손실 함수의 기울기를 따라 가중치를 갱신하는 방식이다.
하지만 전체 데이터셋을 사용하면 계산량이 너무 많아져 학습속도가 느려진다.
이를 해결하기 위해 확률적 경사하강법은 매 반복마다 무작위로 한 개의 샘플 데이터셋을 추출하여 가중치를 갱신한다.
- 모맨텀
경사 하강법이 단순히 기울기를 따르는 것이 아니라, 이전 업데이트 방향성을 고려하여 관성을 갖도록 하는 기법이다.
- AdaGrad
학습률을 개별 파라미터마다 다르게 적용하는 기법이다.
자주 업데이트 되는 파라미터의 학습률은 작아지고, 드물게 업데이트되는 파라미터의 학습률은 커지도록 조정한다.
AdaGrad는 초반 학습 속도가 빠르지만, 기울기의 제곱합이 계속 누적되면서 학습률이 급격히 감소하여 학습이 멈출 수도 있다.
- RMSprop
AdaGrad의 단점을 개선한 방법으로 최근 기울기의 크기를 지수적으로 가중평균하여 스케일링한다.
(이전의 기울기의 이동 평균을 사용하여 학습률을 조정한다.)
- Adam
모멘텀과 RMSProps를 결합한 방법이다.
1차 모멘텀(기울기의 이동평균)과 2차 모멘텀(기울기 제곱의 이동평균)을 활용해 안정적인 학습이 가능하다.
실습
import numpy as np
import matplotlib.pyplot as plt
- 간단한 SGD
data_sample = np.random.uniform(-2, 2, size=10)
def loss(x):
return x ** 2
def gradient(x):
return 2 * x
def sgd(lr=0.1, epochs=10):
w = np.random.uniform(-2, 2)
history = [w]
for _ in range(epochs):
sample = np.random.choice(data_sample)
grad = gradient(sample)
w -= lr * grad
history.append(w)
return history
history = sgd()
x_vals = np.linspace(-2, 2, 100)
plt.plot(x_vals, loss(x_vals), label='Loss Function')
plt.plot(history, loss(np.array(history)), 'ro-', label='SGD')
plt.legend()
plt.show()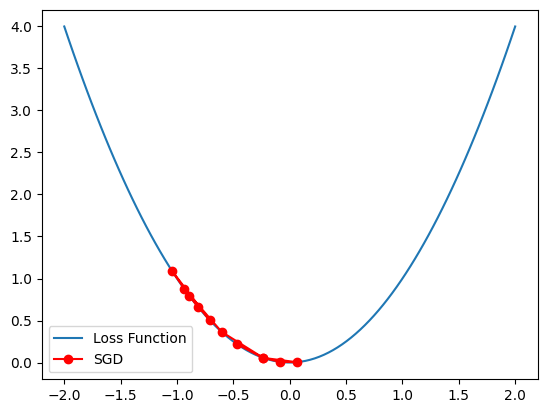
- 모맨텀 추가
def sgd_momentum(lr=0.1, momentum=0.9, epochs=10):
w = np.random.uniform(-2, 2)
v = 0
history = [w]
for _ in range(epochs):
sample = np.random.choice(data_sample)
grad = gradient(sample)
v = momentum * v - lr * grad
w -= lr * grad
history.append(w)
return history
sgd_history = sgd()
momentum_history = sgd_momentum()
x_vals = np.linspace(-2, 2, 100)
plt.plot(x_vals, loss(x_vals), label='Loss Function')
plt.plot(sgd_history, loss(np.array(sgd_history)), 'ro-', label='SGD')
plt.plot(momentum_history, loss(np.array(momentum_history)), 'bo-', label='Momentum')
plt.legend()
plt.show()
- 학습률에 따른 SGD
learning_rates = [0.01, 0.1, 0.5]
histories = [sgd(lr=lr) for lr in learning_rates]
plt.figure(figsize=(5, 3))
for i, history in enumerate(histories):
plt.plot(history, label=f'lr={learning_rates[i]}')
plt.legend()
plt.show()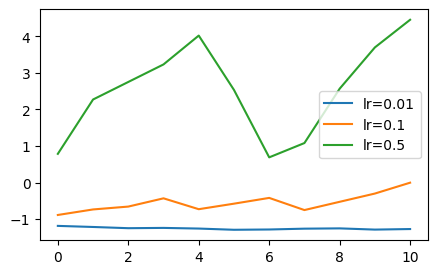
- AdaGrad
def adagrad(lr=0.1, epsilon=1e-8, epochs=10):
w = np.random.uniform(-2, 2)
h = 0
history = [w]
for _ in range(epochs):
grad = gradient(w)
h += grad ** 2
w -= (lr / (np.sqrt(h) + epsilon)) * grad
history.append(w)
return history
sgd_history = sgd()
adagrad_history = adagrad()
x_vals = np.linspace(-2, 2, 100)
plt.plot(x_vals, loss(x_vals), label='Loss Function')
plt.plot(sgd_history, loss(np.array(sgd_history)), 'ro-', label='SGD')
plt.plot(adagrad_history, loss(np.array(adagrad_history)), 'bo-', label='AdaGrad')
plt.legend()
plt.show()
- RMSprop
def rmsprop(lr=0.1, beta=0.9, epsilon=1e-8, epochs=10):
w = np.random.uniform(-2, 2)
h = 0
history = [w]
for _ in range(epochs):
grad = gradient(w)
h += (beta * h) + ((1 - beta) * grad ** 2)
w -= (lr / (np.sqrt(h) + epsilon)) * grad
history.append(w)
return history
adagrad_history = adagrad()
rmsprop_history = rmsprop()
plt.plot(range(11), adagrad_history, 'ro-', label='AdaGrad')
plt.plot(range(11), rmsprop_history, 'bo-', label='RMSprop')
plt.legend()
plt.show()
- Adam
def adam(lr=0.1, beta1=0.9, beta2=0.999, epsilon=1e-8, epochs=10):
w = np.random.uniform(-2, 2)
m, v = 0, 0
history = [w]
for t in range(1, epochs):
grad = gradient(w)
m = beta1 * m + (1 - beta1) * grad
v = beta2 * v + (1 - beta2) * grad ** 2
m_hat = m / (1 - beta1 ** t)
v_hat = v / (1 - beta2 ** t)
w -= (lr / (np.sqrt(v_hat) + epsilon)) * m_hat
history.append(w)
return history
sgd_history = sgd()
adagrad_history = adagrad()
adam_history = adam()
x_vals = np.linspace(-2, 2, 100)
plt.plot(x_vals, loss(x_vals), label = 'Loss Function')
plt.plot(sgd_history, loss(np.array(sgd_history)), 'ro-', label='SGD')
plt.plot(adagrad_history, loss(np.array(adagrad_history)), 'bo-', label='AdaGrad')
plt.plot(adam_history, loss(np.array(adam_history)), 'go-', label='Adam')
plt.legend()
plt.show()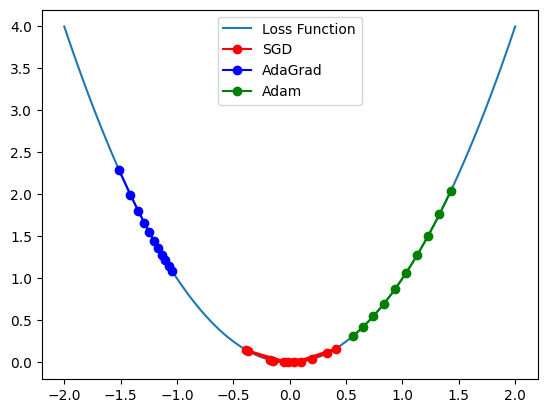
- PyTorch 활용 → SGD vs Adam 비교
import torch
import torch.nn as nn
import torch.optim as optim
torch.manual_seed(42)
X = torch.rand(100, 1) * 10
y = 3 * X + 5 + (torch.randn(100, 1) * 0.3)
model_sgd = nn.Linear(1, 1)
model_adam = nn.Linear(1, 1)
criterion = nn.MSELoss()
optim_sgd = optim.SGD(model_sgd.parameters(), lr=0.01)
optim_adam = optim.Adam(model_adam.parameters(), lr=0.01)
epochs = 100
losses_sgd = []
losses_adam = []
for epoch in range(epochs):
optim_sgd.zero_grad()
outputs = model_sgd(X)
loss = criterion(outputs, y)
loss.backward()
optim_sgd.step()
losses_sgd.append(loss.item())
for epoch in range(epochs):
optim_adam.zero_grad()
outputs = model_adam(X)
loss = criterion(outputs, y)
loss.backward()
optim_adam.step()
losses_adam.append(loss.item())
plt.plot(losses_sgd, label='SGD')
plt.plot(losses_adam, label='Adam')
plt.legend()
plt.show()
'데이터 분석과 머신러닝, 딥러닝 > 딥러닝' 카테고리의 다른 글
| 3.2.21 [딥러닝] 최적 모델 학습 (과적합 해결) (5) | 2025.08.07 |
|---|---|
| 3.2.19 [딥러닝] 최적 모델 학습 (오차역전파법) (1) | 2025.08.05 |
| 3.2.18 [딥러닝] 인공신경망(2) (4) | 2025.08.04 |
| 3.2.16 [딥러닝] 인공신경망 (4) | 2025.08.03 |
| 3.2.15 [딥러닝] 개요 (2) | 2025.08.03 |


