
Developer's Development
[플레이데이터 SK네트웍스 Family AI 캠프 17기] 7주차 회고 본문
Hello World 👋🏻
이번 주는 딥러닝 파트를 조금씩 마무리하고, 2차 프로젝트 준비에 한 걸음을 내딛은 한 주였어요.
처음 딥러닝을 접했을 땐 생소하고 어려운 개념이 많아 막막했지만, 실습과 비유를 통해 하나씩 이해해 가면서 재미를 느낄 수 있었어요.
물론 여전히 갈 길이 멀지만, 지금까지 해온 걸 보니 조금은 스스로를 믿어도 되겠다는 생각이 들어요.
이번 회고에서는 이번 주 학습 내용과 느낀 점을 기록하고, 다음 주를 위한 방향성도 함께 정리해볼게요!
📅 공부 기록
🎯 손실 함수 (Loss Function)
: 모델의 예측이 정답과 얼마나 다른지를 수치로 측정하는 함수
: 우리가 머신러닝 모델을 학습시킬 때 이 손실을 최소화하는 방향으로 파라미터를 바꿔나가게 됨
Huber Loss
: MSE처럼 부드럽고, MAE처럼 이상치에 강한 손실함수
→ 작은 오차엔 정밀하게 반응 (MSE처럼), 큰 오차엔 덜 민감하게 대응 (MAE처럼)
[실습] 신경망 모델에서 손실 함수 활용
- Forward Propagation (순전파): "내가 낸 답이 얼마나 틀렸는지 채점지 작성"
- Backward Propagation (역전파) : "틀린 이유를 거슬러 올라가서 어떤 가중치가 잘못했는지 따져 묻기!"
- 가중치 업데이트: "틀린 걸 반성하고, 다음 시험을 위해 살짝 방향을 바꿈"
▶ "모델아, 지금 얼마나 틀렸는지 알려줄게. 그러니 다음부턴 그 방향으로 고쳐 나가렴" (like 훈육 교사)
🎯 수치 미분 (Numerical Derivative)
: 기울기를 수학적으로 직접 계산하는 게 힘들 때, 아주 작은 변화량으로 근사해서 미분 값을 계산하는 방법
: "앞뒤로 한 발짝씩 움직여서 경사 측정", 공식을 모르니까 몸으로 직접 움직이며 얼마나 변화했는지 확인
[실습] h값에 따른 영향
- h값: "현미경의 초점 거리" → 너무 멀면 대충 봐서 잘 안 보이고, 너무 가까우면 초점이 맞지 않음
▶ 적당한 거리일 때 가장 선명하게 보이는 것처럼, 수치 미분도 적당한 h일 때 정확도가 가장 높음

🎯 기울기 (Gradient)
: 손실 함수가 파라미터에 대해 얼마나 민감하게 변하는지를 나타내는 값
: 학습은 결국 이 기울기를 따라 손실을 줄이는 방향으로 파라미터를 업데이트하는 것
: "눈을 감고 언덕을 내려갈 때, 경사가 없는 평지라면 어디로 가야 할지 몰라", 기울기가 작아지면 방향 감각도 사라짐
[실습] 기울기 소실 문제
- 시그모이드, tanh: "눈치가 빠른 직원" → 살짝만 입력이 바뀌어도 금방 포화 상태가 돼서, 더 이상 변화에 반응을 안 함 (기울기 소실)
- ReLU: "눈치 빠르지만 무뚝뚝한 직원" → 양수일 땐 척척 반응, 음수면 그냥 무시 (죽은 뉴런 문제 발생 가능)
▶ 해결 방법
- 활성화 함수 변경: "벽은 넘기 힘들지만, 평지는 잘 달려!"
→ ReLU (입력이 0 이하이면 0, 크면 그대로 출력), Leaky ReLU (0보다 작을 때도 아주 약한 기울기를 유지)
- 잔차 연결: "길이 막히면 옆길로 우회"
ReLU는 기울기를 살리고, Residual은 정보를 지킨다.
🎯 오차역전파법 (Backpropagation)
: 출력층에서 계산된 오차를 뒤로(backward) 보내며 각 층의 가중치가 학습에 얼마나 영향을 미쳤는지 계산
: "거울이 깨졌다면, 깨진 흔적을 따라 거슬러 올라가면서 누가 얼마나 잘못했는지 따져보는 것"
⭐ 오차역전파법 동작 과정
순전파 → 손실 계산 → 역전파 → 가중치 업데이트 → 오차가 최소화될 때까지 반복
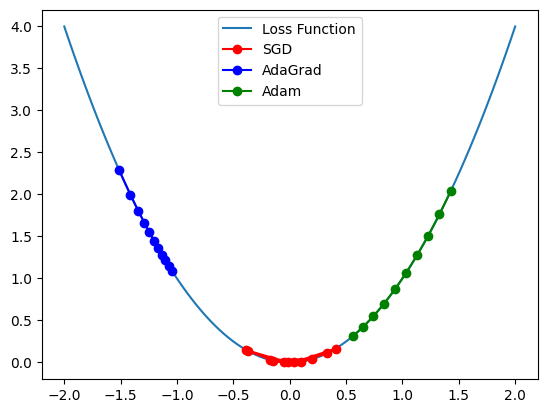
🎯 최적화 함수
: "파라미터를 얼마나, 어떻게 움직일지" 결정
- SGD(확률적 경사 하강) : 안대 쓰고 산 타기 (매번 "지금 발 밑이 어디로 기울어졌나"만 보고 한 걸음씩 걷는 느낌)
- 모맨텀 : 볼링공 굴리기 (처음엔 천천히 출발하지만, 관성으로 점점 빨라짐)
- AdaGrad : 오답 노트를 쓰는 학생 (자주 틀린 문제는 덜 공부하고, 덜 틀린 문제는 더 열심히 복습함)
- RMSprop : 샤워 온도 조절 (과거의 온도 설정 전체를 기억하는 게 아니라, 최근 몇 초간의 온도 변화만 참고해서 조절)
- Adam : 하이브리드 자동차 내비게이션 (과거 주행속도와 도로 상황을 같이 고려해서 가장 빠르고 안정적으로 목적지 도달)
| Optimizer | 핵심 특징 | 장단점 |
| SGD | 현재 기울기만 사용 | 계산량이 적고 직관적 / 수렴 속도가 느림 |
| 모맨텀 | 기울기 + 관성 사용 | 빠른 수렴, 지역 최소점 극복 가능 / 적절한 모맨텀 계수 설정 필요 |
| AdaGrad | 자주 업데이트되는 파라미터는 학습률 감소 | 개별 학습률 조정 가능 / 학습률이 너무 작아질 수 있음 |
| RMSprop | 최근 기울기만 반영해 학습률 조정 | 학습률 감소 문제 해결 / 적절한 β 값 조정 필요 |
| Adam | 모맨텀 + RMSprop | 빠른 수렴, 튜닝 용이 / 일반화 성능이 낮을 수 있음 |
🎯 과적합 (Overfitting)
"교과서 문제만 줄줄 외우고 실제 시험에서 엉뚱한 문제는 못 푸는 상황"
- 배치 정규화: 수업 전 스트레칭 (매번 같은 자세로 공부할 수 있게 입력 값을 정규화해서 준비시키면, 몸이 풀려서 더 잘 받아들임)
- 드롭아웃: 학생에게 랜덤 하게 친구 도움 금지하기 (오늘 이 친구는 질문 금지! 하면 스스로도 학습하고, 실력이 고르게 분산)
- 하이퍼파라미터 최적화: 공부 계획표 짜기 (계획표를 다양하게 짜 보면서, 가장 효율적인 공부 루틴을 찾는 과정)
- 조기 종료: 시험공부, 딱 거기까지만! (지금 그만 공부하고 푹 자! 타이밍 좋게 멈추는 전략)
- 데이터 증강: 시험 예상 문제 다양하게 바꿔 풀기 (문제를 다양한 각도에서 풀어보는 것)
- 정규화: 답을 적을 때, 간결하게 말하기 훈련 (L1: 덜 중요한 건 아예 0으로, L2: 덜 중요한 건 작게라도 줄여서)
| 전략 | 개념 | 핵심 목적 |
| 배치 정규화 | 각 층의 입력 분포를 정규화하여 학습 안정화 | 입력 분포 표준화로 안정적 학습 |
| 드롭아웃 | 학습 시 일부 뉴런을 무작위로 껴서 과적합 방지 | 특정 뉴런 의존 줄이기 |
| 하이퍼파라미터 최적화 | 학습률, 배치 크기, 은닉층 크기 등 최적 조합 찾기 | 최고의 학습 설정 찾기 |
| 조기 종료 | 검증 손실이 증가하면 학습을 중단 | 최적 타이밍에 학습 종료 |
| 데이터 증강 | 기존 데이터를 회전, 확대, 노이즈 추가 등으로 변형 | 데이터 다양성으로 일반화 향상 |
| 정규화 (L1/L2) | 모델 복잡도를 줄이는 패널티 항 추가 | 복잡도 감소 및 과적합 방지 |
[실습] 배치 정규화 적용
- fc1, fc2, fc3: "과목 선생님" → 입력 데이터를 가공해서 다음 정보로 넘겨주는 역할
- relu(): "하이라이트 펜" → 중요한 부분을 강조해 학습 효과를 높임
- BatchNorm1d: "준비운동 트레이너" → 학습 전에 몸풀기를 시켜줘서 부상의 위험을 낮춤
▶ 이 과정을 반복하면서 학생의 실력(모델 성능)이 점점 좋아짐

[실습] 드롭아웃 적용
"항상 같은 사람만 발표하게 하면 그 사람만 늘고, 나머진 못 늘어요"
▶ 여러 조합으로 다양한 상황을 연습하게 해서, 실제 테스트 상황(검증 셋)에서도 잘 작동하게 해 줌
0.2 : 대부분 참석 (한 두 명 빠져도 팀이 잘 돌아감)
0.5 : 절반 참석 (서로 많이 의지하며, 골고루 참여)
0.8 : 거의 다 빠짐 (거의 혼자 발표하듯, 학습이 어려워질 수도 있음)

[실습] 조기 종료
"면접을 준비하는 대학생이 면접 대비 스터디를 하면서, 매일 연습하며 점수를 확인함"
patience=5: "엄마의 인내심" → 점수가 안 오르면 5일까진 기다리고, 6일째도 그대로면 연습 종료시킴
min_delta=0.001: "기대치 컷" → 하루에 0.001점 이상 올라야 진짜 발전으로 인정, 미만이면 patience 카운트 올라감

[실습] L2 적용
"근육 키우는 두 트레이너의 방식"
- 트레이너A (L2 X): "더 큰 근육! 더 많은 중량! 끝까지 밀어!" → 모델은 점점 복잡하고 무거운 (큰 가중치) 근육을 키워감
- 트레이너B (L2 O): "너무 근육만 키우면 안 돼. 심플하게, 효율적으로 ㄱㄱ!" → 가중치가 너무 커지면 패널티를 줘서 모델이 단순해지도록 유도함

💭 KPT
Keep (현재 만족하고 있는 부분, 계속 이어갔으면 하는 부분)
이번 주는 개념을 단순 암기보다 이해 중심으로 정리하려고 노력했어요.
복잡한 수식 대신 비유를 떠올리며 공부하다 보니 어려운 내용도 훨씬 쉽게 기억에 남았어요.
특히, 최적화 함수나 최적화 기법처럼 여러 방법이 존재하는 주제는 비교표와 실습 결과를 함께 기록해 두니 다시 봤을 때도 흐름이 잘 잡혔어요.
무엇보다 이번 주는 계획한 학습 분량을 무리 없이 소화하면서 성취감을 느낄 수 있었고, 이 흐름을 이어가는 것이 중요하다고 생각해요.
앞으로도 비유와 실습 기록을 병행하며 이해도를 높이고, 정리 습관을 꾸준히 유지하려고 해요.
Problem (불편하게 느끼는 부분, 개선이 필요하다고 생각되는 부분)
요즘 공부할 때 가끔 '이걸 왜 하고 있지?' 하는 생각이 들 때가 있어요.
처음엔 재미있고 신났는데, 반복되는 이론과 실습에 지치면서 동기부여가 떨어지더라고요.
그럴 때는 공부하는 시간이 부담스럽게 느껴지고, 집중도 자연스럽게 흐트러져서 속상했어요.
이런 마음이 계속되면 결국 공부를 미루거나 효율이 떨어질까 봐 걱정돼요.
Try (Problem에 대한 해결책, 실행 가능한 것)
그래서 다음 주부터는 내가 공부하는 이유를 다시 한번 떠올리려고 해요.
작은 목표를 세워서, 하나씩 달성할 때마다 스스로 칭찬해 주는 것도 좋고요!
또, 공부하면서 궁금한 점은 바로바로 기록해서 나중에 해결할 수 있게 준비할 생각이에요.
이런 방법들이 동기부여를 회복하고 집중력을 유지하는 데 도움이 될 거라고 믿어요.
이번 주는 배운 내용을 하나하나 다시 정리하면서, '아, 그래도 내가 이만큼은 할 줄 아는 사람이구나' 하는 자신감이 조금은 생겼어요.
물론 여전히 모르는 것도 많고, 실습하다가 막히는 순간도 있지만, 예전처럼 무작정 헤매는 느낌은 아니더라고요.
이제는 뭔가 안 되면 어디서부터 확인해야 할지 감이 잡히는 게 제일 큰 변화 같아요.
프로젝트가 본격적으로 시작되면 더 많은 변수와 문제들이 생기겠지만, 이번 주에 쌓아둔 공부 습관과 정리 방법이 분명 도움이 될 거라고 믿어요.
다음 주에는 더 다양한 실험을 해보고, 팀원들과 아이디어를 주고받으면서 서로의 생각을 넓히는 시간을 많이 가지려고 해요.
이렇게 매주 한 걸음씩 나아가다 보면, 나중에는 우리가 상상했던 결과를 현실로 만들 수 있을 거라 생각해요.
이번 주도 다들 고생 많았고, 다음 주에도 파이팅 해요! 🏃♀️
'회고' 카테고리의 다른 글
| [플레이데이터 SK네트웍스 Family AI 캠프 17기] 9주차 회고 (6) | 2025.08.24 |
|---|---|
| [플레이데이터 SK네트웍스 Family AI 캠프 17기] 8주차 회고 (1) | 2025.08.21 |
| [플레이데이터 SK네트웍스 Family AI 캠프 17기] 6주차 회고 (8) | 2025.08.03 |
| [플레이데이터 SK네트웍스 Family AI 캠프 17기] 5주차 회고 (1) | 2025.08.03 |
| [플레이데이터 SK네트웍스 Family AI 캠프 17기] 4주차 회고 (5) | 2025.07.20 |
