
Developer's Development
3.3.4 [NLP] 자연어 딥러닝(시퀀스 모델링) 본문
자연어 딥러닝
텍스트 데이터에 대해 신경망 모델을 활용하여 의미를 학습하고 작업을 수행하는 방법론
- 시퀀스 데이터/순차 데이터
Sequential Data(순차 데이터)는 데이터의 요소들이 특정한 순서로 정렬되어 있고, 이 순서가 데이터의 의미를 결정하는 데이터 유형이다.시간, 순서, 위치 등 순차적인 흐름을 따르는 데이터를 포함한다. 일반적으로 자연어 처리, 시계열 분석, 음성 신호 처리, 주식 데이터, 센서 데이터 등 다양한 응용 분야에서 활용된다.
👉🏻 특징
순서의 중요성, 시점 정보 포함, 연속성
👉🏻 예시
Speech recognition, Music generation, Sentiment classification, DNA 분석, 자동 번역, Video activity recognition, Financial Data 등
👉🏻 분석 방법
1. 통계적 분석: 이동 평균, 분산 분석 등을 통해 시간 또는 순서의 변화 패턴 파악
2. 머신러닝: RNN, LSTM, GRU 등 순차 데이터 학습을 위한 신경망 사용
3. 트랜스포머 모델: 자연어 처리 및 시계열 분석에서 효율적으로 순차적 패턴을 학습
순환 신경망 (RNN)
RNN(Recurrent Neural Network)은 순차적인 데이터(시퀀스 데이터)를 처리하기 위한 신경망 구조다. 순환 구조를 통해 이전 상태의 정보를 현재 상태로 전달한다,
RNN은 입력 데이터의 시간적 순서를 고려하여 정보를 처리하며, 특히 텍스트, 음성, 시계열 데이터 등에서 많이 사용된다.

- 순환 구조: RNN은 이전의 출력 또는 은닉 상태를 다음 계산에 반영하여 시간에 따른 정보를 기억한다.
- 은닉 상태(Hidden State): 이전 시점의 정보를 현재 시점으로 전달하는 역할을 한다.
- 시간 전개(Time Unfolding): 시퀀스의 길이에 따라 동일한 구조가 반복되며, 각 시점마다 입력과 은닉 상태를 업데이트한다.
→ RNN을 순서대로 펼쳐 놓으면 weight을 공유하는 매우 깊은 신경망이 된다.
→ RNN의 오차역전파는 BPTT(Backpropagation Through Time)으로 처리된다.
👉🏻 특징
- 특화: 시퀀스 데이터 처리에 강점
- 기억 능력: 이전 능력을 '기억'하며 처리
- 네트워크는 입력 데이터를 요약하여 기억을 저장
- 새로운 입력이 들어올 때마다 기억을 조금씩 수정
- 모든 입력을 처리한 후, 남은 기억은 시퀀스를 전체적으로 요약하는 정보로 활용
- 반복적 처리: 입력마다 기억을 갱신하며 순환적으로 진행 (사람이 단어를 기억하며 이해하는 방식과 유사)
👉🏻 RNN 구현체
1. RNN: 단순 구조, 기울기 소멸 문제 발생
2. LSTM: 게이트 구조 추가로 장기 의존성을 처리
3. GRU: LSTM보다 간단한 구조로 비슷한 성능 제공
👉🏻 적용 분야
언어 모델링, 기계 번역, 감성 분석
👉🏻 한계
장기 의존성 문제(Long-Term-Dependency): 오래된 과거 정보가 현재 출력에 반영되지 못하는 문제가 발생한다.
그래디언트 소실 문제(Vanishing Gradient): 역전파 과정에서 기울기가 매우 작아지거나 커져 학습이 어려워진다.
LSTM (Long Short-Term Memory)
RNN의 일종으로, 기존 RNN의 장기 의존성 문제를 해결하기 위해 고안된 구조로 정보의 흐름을 조절하는 게이트(Gate) 메커니즘을 도입하였다. 셀 상태(Cell State)를 추가하여 정보를 기억하거나 잊는다.
❗ 셀 상태(Cell State): 정보를 지속적으로 전달하는 경로로, 불필요한 정보는 게이트를 통해 제거
- 특징
1. 장기 의존성(Long-Term Dependency) 처리
- 일반적인 RNN은 시간이 길어질수록 과거의 정보를 잘 기억하지 못하는 기울기 소멸 문제가 발생한다.
- LSTM은 Cell State와 게이트 구조를 통해 중요한 정보를 장기적으로 유지할 수 있다.
2. 게이트(Gate) 구조
- LSTM은 정보를 선택적으로 기억하거나 잊게 해주는 3가지 게이트로 구성된다.
- 입력 게이트(Input Gate): 새로운 정보를 얼마나 저장할지 결정한다.
- 망각 게이트(Forget Gate): 기존 정보를 얼마나 잊을지 결정한다.
- 출력 게이트(Output Gate): 현재 상태를 출력에 얼마나 반영할지 결정한다.
3. Cell State
- 네트워크의 기억 장치 역할을 하며, 중요하지 않은 정보는 제거하고 중요한 정보는 유지한다.
- 주요 구조
1. 망각 게이트
2. 입력 게이트
3. Cell State 업데이트
4. 출력 게이트
- 장점
1. 장기 시퀀스 데이터 처리
2. 텍스트, 음성, 시계열 데이터에 적합
3. 기울기 소멸 문제 해결
✔️ Bidirectional LSTM
LSTM의 변형 모델로, 양방향으로 데이터를 처리할 수 있도록 설계된 구조이다. 일반 LSTM이 입력 데이터를 순방향(forward)으로만 처리하는 반면, Bidirectional LSTM은 순방향과 역방향(backward)으로 데이터를 동시에 처리하여 더 많은 정보를 학습한다.
GRU (Gated Recurrent Unit)
RNN의 변형 구조 중 하나로, LSTM과 유사하지만 게이트 수를 줄여 구조가 더 간단하다. GRU는 게이트 구조를 사용해 RNN의 기울기 소멸 문제를 해결하면서도, 연산량을 줄이고 효율적으로 학습할 수 있도록 설계되었다. (문제에 따라 LSTM보다 더 나은 경우도 있다.)
- 특징
1. 단순화된 구조
2. 장단기 의존성 처리
3. 연산 효율성
- GRU의 게이트 구조
1. 리셋 게이트(Reset Gate)
- 과거 정보를 얼마나 잊을지 결정하며, 이전 은닉 상태가 현재 입력에 얼마나 반영될지를 제어한다.
2. 은닉 상태 업데이트
- 새로운 은닉 상태는 리셋 게이트를 적용한 이전 은닉 상태와 현재 입력 정보를 결합하여 생성된다.
3. 업데이트 게이트(Update Gate)
- 정보의 기억 여부를 결정하며, 이전 시점의 정보와 현재 입력 정보를 결합하여 다음 은닉 상태에 어떤 정보를 전달할지 제어한다.
4. 최종 은닉 상태
- 업데이트 게이트를 사용해 이전 은닉 상태와 새로운 은닉 상태를 조합하여 최종 은닉 상태를 계산한다.
- LSTM과 GRU의 비교
| 특징 | LSTM | GRU |
| 게이트 수 | 3개 (입력, 망각, 출력 게이트) | 2개 (업데이트, 리셋 게이트) |
| 상태 | 셀 상태(Cell State), 은닉 상태(Hidden State) | 은닉 상태(Hidden State)만 사용 |
| 구조의 복잡성 | 복잡함 | 단순함 |
| 계산량 | 상대적으로 많음 | 상대적으로 적음 |
| 성능 차이 | 복잡한 시퀀스 데이터에 강점 | 빠르고 간단한 시퀀스 데이터에 적합 |
✔️ Bidirectional GRU
cell State가 없는 것 외에 LSTM과 동일하다.
GRU의 양방향 변형 모델로, 데이터를 순방향과 역방향으로 동시에 처리하여 더 풍부한 정보를 학습할 수 있다.
실습 (RNN (by Tensorflow))
VOCAB_SIZE = 300 # 사용할 단어 수
SEQ_LEN = 100 # 시퀀스 하나의 최대 길이
- 데이터 준비
from tensorflow.keras.datasets import imdb
from tensorflow.keras.preprocessing.sequence import pad_sequences
from tensorflow.keras.utils import to_categorical
(train_input, train_target), (test_input, test_target) = imdb.load_data(num_words=VOCAB_SIZE) # 데이터를 로드해서 반환 (상위 300개만)
train_input.shape, train_target.shape, test_input.shape, test_target.shape # ((25000,), (25000,), (25000,), (25000,))
# 데이터가 너무 많으니까 조금 자르기
train_input, test_input = train_input[:10000], test_input[:5000]
train_target, test_target = train_target[:10000], test_target[:5000]
train_seq = pad_sequences(train_input, maxlen=SEQ_LEN)
test_seq = pad_sequences(test_input, maxlen=SEQ_LEN)
train_seq.shape, test_seq.shape # ((10000, 100), (5000, 100))
train_onehot = to_categorical(train_seq)
test_onehot = to_categorical(test_seq)
train_onehot.shape, test_onehot.shape # ((10000, 100, 300), (5000, 100, 300))
- 모델 준비 및 학습
from tensorflow.keras import models, layers, callbacks, optimizers
input = layers.Input(shape=(SEQ_LEN, VOCAB_SIZE))
x = layers.SimpleRNN(units=8)(input) # 은닉층 노드 개수 8개
output = layers.Dense(1, activation='sigmoid')(x)
model = models.Model(input, output)
model.summary()
import pandas as pd
import matplotlib.pyplot as plt
model.compile(loss='binary_crossentropy', optimizer='adam', metrics=['accuracy'])
# 콜백 인스턴스 생성
early_stopping_cb = callbacks.EarlyStopping(patience=7, restore_best_weights=True, verbose=1) # 7번까지 참고 조기종료, verbose: 과정 현출
reduce_lr_on_plateau_cb = callbacks.ReduceLROnPlateau(patience=3, factor=0.7, verbose=1) # 학습을 진행하는 과정에서 3번 연속 좋아지지 않으면 학습률 70% 정도 감소시켜라
history = model.fit(
train_onehot,
train_target,
epochs=100, # 반복 횟수(학습 횟수)
batch_size=65, # 미니 배치 65개
validation_split=0.2, # 검증셋(검증용을 20%로 자동 분리)
callbacks=[early_stopping_cb, reduce_lr_on_plateau_cb]
)
history_df = pd.DataFrame(history.history)
history_df.plot()
plt.show()
loss, accuracy = model.evaluate(test_onehot, test_target)
loss, accuracy
"""
157/157 ━━━━━━━━━━━━━━━━━━━━ 1s 4ms/step - accuracy: 0.7182 - loss: 0.5687
(0.5686802268028259, 0.7182000279426575)
"""
실습 (RNN (by PyTorch))
VOCAB_SIZE = 300 # 사용할 단어 수
SEQ_LEN = 150 # 시퀀스 하나의 최대 길이
- 데이터 준비
from tensorflow.keras.datasets import imdb
import torch
import matplotlib.pyplot as plt
(train_input, train_target), (test_input, test_target) = imdb.load_data(num_words=VOCAB_SIZE)
# Torch Tensor 변환
train_input = [torch.tensor(seq, dtype=torch.long) for seq in train_input][:10000]
test_input = [torch.tensor(seq, dtype=torch.long) for seq in test_input][:5000]
train_target = torch.tensor(train_target, dtype=torch.long)[:10000]
test_target = torch.tensor(test_target, dtype=torch.long)[:5000]
# 시퀀스 길이 빈도 확인 (시각화)
train_len = [len(seq) for seq in train_input]
plt.hist(train_len, bins=20)
plt.xlabel('seq_len')
plt.ylabel('freq')
plt.show()
import torch.nn.functional as F
# 패딩 처리
def pad_sequences(sequences, maxlen, padding_value=0):
padded_sequences = [F.pad(seq[:maxlen], (0, max(0, maxlen-len(seq))), # 패딩할 길이를 정함 (음수면 0으로 채우기)
value=padding_value) for seq in sequences]
return torch.stack(padded_sequences)
train_seq = pad_sequences(train_input, maxlen=SEQ_LEN)
test_seq = pad_sequences(test_input, maxlen=SEQ_LEN)
# 원핫인코딩 처리
train_onehot = F.one_hot(train_seq, num_classes=VOCAB_SIZE).float()
test_onehot = F.one_hot(test_seq, num_classes=VOCAB_SIZE).float()
train_onehot.shape, test_onehot.shape # (torch.Size([10000, 150, 300]), torch.Size([5000, 150, 300]))
- 모델 준비 및 학습
import torch.nn as nn
# 간단한 RNN 모델 정의
class SentimentRNN(nn.Module):
def __init__(self, seq_len, vocab_size, hidden_dim, output_dim):
super(SentimentRNN, self).__init__()
self.rnn = nn.RNN(input_size=vocab_size, hidden_size=hidden_dim, batch_first=True)
self.fc = nn.Linear(hidden_dim, output_dim)
self.sigmoid = nn.Sigmoid()
def forward(self, x):
_, hidden = self.rnn(x)
out = self.fc(hidden.squeze(0))
return self.sigmoid(out)
HIDDEN_DIM = 8
OUTPUT_DIM = 1
model = SentimentRNN(
seq_len=SEQ_LEN,
vocab_size=VOCAB_SIZE,
hidden_dim=HIDDEN_DIM,
output_dim=OUTPUT_DIM
)
print(model)
"""
SentimentRNN(
(rnn): RNN(300, 8, batch_first=True)
(fc): Linear(in_features=8, out_features=1, bias=True)
(sigmoid): Sigmoid()
)
"""# 학습을 위한 설정
import torch.optim as optim
import pandas as pd
from torch.utils.data import DataLoader, TensorDataset, random_split
# 배치 사이즈, 학습/검증셋 크기 설정
BATCH_SIZE = 65
train_size = int(len(train_onehot) * 0.8)
val_size = len(train_onehot) - train_size
# label 데이터 실수 처리
train_target = train_target.float()
test_target = test_target.float()
# 데이터 학습/검증셋 분할
train_dataset, val_dataset = random_split(TensorDataset(train_onehot, train_target), [train_size, val_size])
# 미니배치로 사용할 수 있도록 DataLoader 생성
train_loader = DataLoader(train_dataset, batch_size=BATCH_SIZE, shuffle=True)
val_loader = DataLoader(val_dataset, batch_size=BATCH_SIZE)
# epoch(학습 횟수), 손실 함수, 최적화 함수 정의
epochs = 100
criterion = nn.BCELoss()
optimizer = optim.Adam(model.parameters(), lr=0.005)
# 시각화를 위한 손실값/정확도 저장용 배열 생성
train_losses, val_losses, train_accs, val_accs = [], [], [], []
# 조기종료 관련 변수 초기화
early_stopping_patience = 7
best_val_loss = float('inf')
early_stop_counter = 0# 학습 진행
for epoch in range(epochs):
# 학습 모드
model.train()
total_loss, correct, total = 0, 0, 0
for inputs, targets in train_loader:
optimizer.zero_grad() # 가중치 초기화
outputs = model(inputs).squeeze() # 순전파
loss = criterion(outputs, targets) # 손실 계산
loss.backward() # 역전파
optimizer.step() # 가중치 갱신
total_loss += loss.item()
pred = (outputs > 0.5).float()
correct += (pred == targets).sum().item()
total += targets.size(0)
train_loss = total_loss / len(train_loader)
train_acc = correct / total
train_losses.append(train_loss)
train_accs.append(train_acc)
# 검증 모드
model.eval()
val_loss, val_correct, val_total = 0, 0, 0
with torch.no_grad():
for val_inputs, val_targets in val_loader:
val_outputs = model(val_inputs).squeeze()
loss = criterion(val_outputs, val_targets)
val_loss += loss.item()
val_pred = (val_outputs > 0.5).float()
val_correct += (val_pred == val_targets).sum().item()
val_total += val_targets.size(0)
val_loss = val_loss / len(val_loader)
val_acc = val_correct / val_total
val_losses.append(val_loss)
val_accs.append(val_acc)
print(f'Epoch {epoch + 1}/{epochs} | Train Loss: {train_loss:.4f}, Train Acc: {train_acc:.4f}, Val Loss: {val_loss:.4f}, Val Acc: {val_acc:.4f}')
# 조기 종료
if val_loss < best_val_loss:
best_val_loss = val_loss
early_stop_counter = 0
else:
early_stop_counter += 1
if early_stop_counter >= early_stopping_patience:
print("Early Stopping 할게~~~~~!")
break
"""
Epoch 1/100 | Train Loss: 0.6950, Train Acc: 0.5146, Val Loss: 0.6958, Val Acc: 0.4960
Epoch 2/100 | Train Loss: 0.6900, Train Acc: 0.5266, Val Loss: 0.6982, Val Acc: 0.5085
Epoch 3/100 | Train Loss: 0.6867, Train Acc: 0.5394, Val Loss: 0.6959, Val Acc: 0.5100
Epoch 4/100 | Train Loss: 0.6787, Train Acc: 0.5560, Val Loss: 0.7013, Val Acc: 0.5055
Epoch 5/100 | Train Loss: 0.6660, Train Acc: 0.5727, Val Loss: 0.7144, Val Acc: 0.5080
Epoch 6/100 | Train Loss: 0.6540, Train Acc: 0.5875, Val Loss: 0.7326, Val Acc: 0.4960
Epoch 7/100 | Train Loss: 0.6427, Train Acc: 0.6052, Val Loss: 0.7385, Val Acc: 0.5035
Epoch 8/100 | Train Loss: 0.6334, Train Acc: 0.6084, Val Loss: 0.7506, Val Acc: 0.5075
Early Stopping 할게~~~~~!
"""# 학습 과정 시각화
train_history_df = pd.DataFrame({
'train_loss': train_losses,
'val_loss': val_losses,
'train_acc': train_accs,
'val_acc': val_accs
})
train_history_df.plot()
plt.show()
# 평가 함수 정의
def evaluate_model(model, test_loader, criterion):
model.eval()
val_loss, val_correct, val_total = 0, 0, 0
with torch.no_grad():
for val_inputs, val_targets in test_loader:
val_outputs = model(val_inputs).squeeze()
loss = criterion(val_outputs, val_targets)
val_loss += loss.item()
val_pred = (val_outputs > 0.5).float()
val_correct += (val_pred == val_targets).sum().item()
val_total += val_targets.size(0)
val_loss = val_loss / len(test_loader)
val_acc = val_correct / val_total
return val_loss, val_acc
test_dataset = TensorDataset(test_onehot, test_target)
test_loader = DataLoader(test_dataset, batch_size=BATCH_SIZE)
loss, accuracy = evaluate_model(model, test_loader, criterion)
loss, accuracy # (0.7389129377030706, 0.5164)
실습 (LSTM)
💧 위에서 한 코드 내용들을 함수로 정의해놓기
- 데이터 준비
from tensorflow.keras.datasets import imdb
import torch
import torch.nn.functional as F
VOCAB_SIZE = 300 # 사용할 단어 수
SEQ_LEN = 150 # 시퀀스 하나의 최대 길이
# 데이터 로드
(train_input, train_target), (test_input, test_target) = imdb.load_data(num_words=VOCAB_SIZE)
# Torch Tensor 변환
train_input = [torch.tensor(seq, dtype=torch.long) for seq in train_input][:10000]
test_input = [torch.tensor(seq, dtype=torch.long) for seq in test_input][:5000]
train_target = torch.tensor(train_target, dtype=torch.long)[:10000]
test_target = torch.tensor(test_target, dtype=torch.long)[:5000]
# 패딩 처리
def pad_sequences(sequences, maxlen, padding_value=0):
padded_sequences = [F.pad(seq[:maxlen], (0, max(0, maxlen-len(seq))), value=padding_value) for seq in sequences]
return torch.stack(padded_sequences)
train_seq = pad_sequences(train_input, maxlen=SEQ_LEN)
test_seq = pad_sequences(test_input, maxlen=SEQ_LEN)
# 원핫인코딩 처리
train_onehot = F.one_hot(train_seq, num_classes=VOCAB_SIZE).float()
test_onehot = F.one_hot(test_seq, num_classes=VOCAB_SIZE).float()
# label 데이터 실수 처리
train_target = train_target.float()
test_target = test_target.float()
train_onehot.shape, test_onehot.shape # (torch.Size([10000, 150, 300]), torch.Size([5000, 150, 300]))
- 모델 학습 함수 정의
import torch.nn as nn
import torch.optim as optim
import pandas as pd
from torch.utils.data import DataLoader, TensorDataset, random_split
import matplotlib.pyplot as plt
def train_func(train_data, train_label, model):
# 학습을 위한 설정
# 배치 사이즈, 학습/검증셋 크기 설정
BATCH_SIZE = 65
train_size = int(len(train_data) * 0.8)
val_size = len(train_data) - train_size
# 데이터 학습/검증셋 분할
train_dataset, val_dataset = random_split(TensorDataset(train_data, train_label), [train_size, val_size])
# 미니배치로 사용할 수 있도록 DataLoader 생성
train_loader = DataLoader(train_dataset, batch_size=BATCH_SIZE, shuffle=True)
val_loader = DataLoader(val_dataset, batch_size=BATCH_SIZE)
# epoch(학습 횟수), 손실 함수, 최적화 함수 정의
epochs = 100
criterion = nn.BCELoss()
optimizer = optim.Adam(model.parameters(), lr=0.005)
# 시각화를 위한 손실값/정확도 저장용 배열 생성
train_losses, val_losses, train_accs, val_accs = [], [], [], []
# 조기종료 관련 변수 초기화
early_stopping_patience = 7
best_val_loss = float('inf')
early_stop_counter = 0
# 학습 진행
for epoch in range(epochs):
# 학습 모드
model.train()
total_loss, correct, total = 0, 0, 0
for inputs, targets in train_loader:
optimizer.zero_grad() # 가중치 초기화
outputs = model(inputs).squeeze() # 순전파
loss = criterion(outputs, targets) # 손실 계산
loss.backward() # 역전파
optimizer.step() # 가중치 갱신
total_loss += loss.item()
pred = (outputs > 0.5).float()
correct += (pred == targets).sum().item()
total += targets.size(0)
train_loss = total_loss / len(train_loader)
train_acc = correct / total
train_losses.append(train_loss)
train_accs.append(train_acc)
# 검증 모드
model.eval()
val_loss, val_correct, val_total = 0, 0, 0
with torch.no_grad():
for val_inputs, val_targets in val_loader:
val_outputs = model(val_inputs).squeeze()
loss = criterion(val_outputs, val_targets)
val_loss += loss.item()
val_pred = (val_outputs > 0.5).float()
val_correct += (val_pred == val_targets).sum().item()
val_total += val_targets.size(0)
val_loss = val_loss / len(val_loader)
val_acc = val_correct / val_total
val_losses.append(val_loss)
val_accs.append(val_acc)
print(f'Epoch {epoch + 1}/{epochs} | Train Loss: {train_loss:.4f}, Train Acc: {train_acc:.4f}, Val Loss: {val_loss:.4f}, Val Acc: {val_acc:.4f}')
# 조기 종료
if val_loss < best_val_loss:
best_val_loss = val_loss
early_stop_counter = 0
else:
early_stop_counter += 1
if early_stop_counter >= early_stopping_patience:
print("Early Stopping 할게~~~~~!")
break
# 학습 과정 시각화
train_history_df = pd.DataFrame({
'train_loss': train_losses,
'val_loss': val_losses,
'train_acc': train_accs,
'val_acc': val_accs
})
train_history_df.plot()
plt.show()
- 평가 함수 정의
# 평가 함수 정의
def evaluate_model(model, test_loader, criterion):
model.eval()
val_loss, val_correct, val_total = 0, 0, 0
with torch.no_grad():
for val_inputs, val_targets in test_loader:
val_outputs = model(val_inputs).squeeze()
loss = criterion(val_outputs, val_targets)
val_loss += loss.item()
val_pred = (val_outputs > 0.5).float()
val_correct += (val_pred == val_targets).sum().item()
val_total += val_targets.size(0)
val_loss = val_loss / len(test_loader)
val_acc = val_correct / val_total
return val_loss, val_acc
- 모델 준비 및 학습
👉🏻 LSTM (+ One-hot Encoding)
import torch
import torch.nn as nn
class SentimentLSTM(nn.Module):
def __init__(self, seq_len, vocab_size, hidden_dim, output_dim):
super(SentimentLSTM, self).__init__()
self.lstm = nn.LSTM(input_size=vocab_size, hidden_size=hidden_dim, batch_first=True)
self.fc = nn.Linear(hidden_dim, output_dim)
self.sigmoid = nn.Sigmoid()
def forward(self, x):
_, (hidden, _) = self.lstm(x)
out = self.fc(hidden)
return self.sigmoid(out)
HIDDEN_DIM = 8
OUTPUT_DIM = 1
lstm_model = SentimentLSTM(
seq_len=SEQ_LEN,
vocab_size=VOCAB_SIZE,
hidden_dim=HIDDEN_DIM,
output_dim=OUTPUT_DIM
)
print(lstm_model)
"""
SentimentLSTM(
(lstm): LSTM(300, 8, batch_first=True)
(fc): Linear(in_features=8, out_features=1, bias=True)
(sigmoid): Sigmoid()
)
"""
train_func(train_onehot, train_target, lstm_model)
test_dataset = TensorDataset(test_onehot, test_target)
test_loader = DataLoader(test_dataset, batch_size=65)
criterion = nn.BCELoss()
loss, accuracy = evaluate_model(lstm_model, test_loader, criterion)
loss, accuracy # (0.5591089133318369, 0.7356)
👉🏻 LSTM (+ Embedding)
class EBDSentimentLSTM(nn.Module):
def __init__(self, vocab_size, embedding_dim, hidden_dim, output_dim):
super(EBDSentimentLSTM, self).__init__()
self.embedding = nn.Embedding(num_embeddings=vocab_size, embedding_dim=embedding_dim)
self.lstm = nn.LSTM(input_size=embedding_dim, hidden_size=hidden_dim, batch_first=True)
self.fc = nn.Linear(hidden_dim, output_dim)
self.sigmoid = nn.Sigmoid()
def forward(self, x):
x = self.embedding(x)
_, (hidden, _)= self.lstm(x)
out = self.fc(hidden)
return self.sigmoid(out)
HIDDEN_DIM = 8
OUTPUT_DIM = 1
EMBEDDING_DIM = 50
ebd_lstm_model = EBDSentimentLSTM(
vocab_size=VOCAB_SIZE,
embedding_dim=EMBEDDING_DIM,
hidden_dim=HIDDEN_DIM,
output_dim=OUTPUT_DIM
)
print(ebd_lstm_model)
"""
EBDSentimentLSTM(
(embedding): Embedding(300, 50)
(lstm): LSTM(50, 8, batch_first=True)
(fc): Linear(in_features=8, out_features=1, bias=True)
(sigmoid): Sigmoid()
)
"""
train_func(train_seq.to(torch.long), train_target, ebd_lstm_model)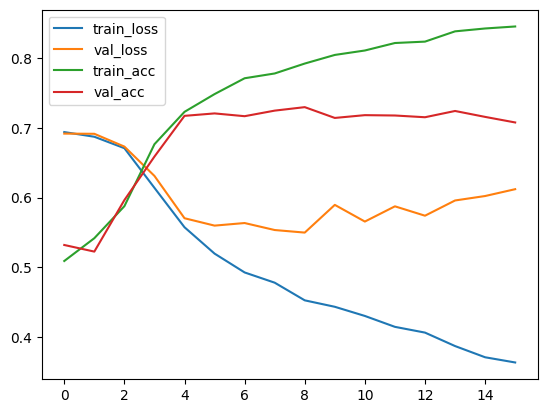
test_dataset = TensorDataset(test_seq.to(torch.long), test_target)
test_loader = DataLoader(test_dataset, batch_size=65)
criterion = nn.BCELoss()
loss, accuracy = evaluate_model(ebd_lstm_model, test_loader, criterion)
loss, accuracy # (0.6339584546429771, 0.7094)
👉🏻 Stacked LSTM (Embedding + LSTM + LSTM)
class StackedSentimentLSTM(nn.Module):
def __init__(self, vocab_size, embedding_dim, hidden_dim, output_dim):
super(StackedSentimentLSTM, self).__init__()
self.embedding = nn.Embedding(num_embeddings=vocab_size, embedding_dim=embedding_dim)
self.lstml = nn.LSTM(input_size=embedding_dim, hidden_size=hidden_dim, batch_first=True)
self.lstm2 = nn.LSTM(input_size=hidden_dim, hidden_size=hidden_dim, batch_first=True)
self.fc = nn.Linear(hidden_dim, output_dim)
self.sigmoid = nn.Sigmoid()
def forward(self, x):
x = self.embedding(x)
x, _ = self.lstml(x)
_, (hidden, _) = self.lstm2(x)
out = self.fc(hidden)
return self.sigmoid(out)
HIDDEN_DIM = 8
OUTPUT_DIM = 1
EMBEDDING_DIM = 50
stacked_lstm_model = StackedSentimentLSTM(
vocab_size=VOCAB_SIZE,
embedding_dim=EMBEDDING_DIM,
hidden_dim=HIDDEN_DIM,
output_dim=OUTPUT_DIM
)
print(stacked_lstm_model)
"""
StackedSentimentLSTM(
(embedding): Embedding(300, 50)
(lstml): LSTM(50, 8, batch_first=True)
(lstm2): LSTM(8, 8, batch_first=True)
(fc): Linear(in_features=8, out_features=1, bias=True)
(sigmoid): Sigmoid()
)
"""
train_func(train_seq.to(torch.long), train_target, stacked_lstm_model)
test_dataset = TensorDataset(test_seq.to(torch.long), test_target)
test_loader = DataLoader(test_dataset, batch_size=65)
criterion = nn.BCELoss()
loss, accuracy = evaluate_model(stacked_lstm_model, test_loader, criterion)
loss, accuracy # (0.6189461663945929, 0.7168)
👉🏻 Stacked LSTM (Embedding + LSTM + LSTM + Dropout)
class StackedDOSentimentLSTM(nn.Module):
def __init__(self, vocab_size, embedding_dim, hidden_dim, output_dim, dropout_rate):
super(StackedDOSentimentLSTM, self).__init__()
self.embedding = nn.Embedding(num_embeddings=vocab_size, embedding_dim=embedding_dim)
self.lstml = nn.LSTM(input_size=embedding_dim, hidden_size=hidden_dim, batch_first=True)
self.dropout1 = nn.Dropout(p=dropout_rate)
self.lstm2 = nn.LSTM(input_size=hidden_dim, hidden_size=hidden_dim, batch_first=True)
self.dropout2 = nn.Dropout(p=dropout_rate)
self.fc = nn.Linear(hidden_dim, output_dim)
self.sigmoid = nn.Sigmoid()
def forward(self, x):
x = self.embedding(x)
x, _ = self.lstml(x)
x = self.dropout1(x)
_, (hidden, _) = self.lstm2(x)
x = self.dropout2(hidden)
out = self.fc(x)
return self.sigmoid(out)
HIDDEN_DIM = 8
OUTPUT_DIM = 1
EMBEDDING_DIM = 50
DROPOUT_RATE = 0.3
stacked_do_lstm_model = StackedDOSentimentLSTM(
vocab_size=VOCAB_SIZE,
embedding_dim=EMBEDDING_DIM,
hidden_dim=HIDDEN_DIM,
output_dim=OUTPUT_DIM,
dropout_rate=DROPOUT_RATE
)
print(stacked_do_lstm_model)
"""
StackedDOSentimentLSTM(
(embedding): Embedding(300, 50)
(lstml): LSTM(50, 8, batch_first=True)
(dropout1): Dropout(p=0.3, inplace=False)
(lstm2): LSTM(8, 8, batch_first=True)
(dropout2): Dropout(p=0.3, inplace=False)
(fc): Linear(in_features=8, out_features=1, bias=True)
(sigmoid): Sigmoid()
)
"""
train_func(train_seq.to(torch.long), train_target, stacked_do_lstm_model)
test_dataset = TensorDataset(test_seq.to(torch.long), test_target)
test_loader = DataLoader(test_dataset, batch_size=65)
criterion = nn.BCELoss()
loss, accuracy = evaluate_model(stacked_do_lstm_model, test_loader, criterion)
loss, accuracy # (0.5854049607530817, 0.7262)
실습 (GRU)
💧 데이터 준비, 모델 학습 함수 정의 코드는 위와 동일
import torch
import torch.nn as nn
class GRUModel(nn.Module):
def __init__(self, input_dim, hidden_units, output_dim, return_sequences=False, return_state=False):
super(GRUModel, self).__init__()
self.return_sequences = return_sequences
self.return_state = return_state
self.gru = nn.GRU(input_size=input_dim, hidden_size=hidden_units, batch_first=True)
self.fc = nn.Linear(hidden_units, output_dim)
self.sigmoid = nn.Sigmoid()
def forward(self, x):
output, hidden = self.gru(x)
result_output = self.fc(hidden[-1])
if self.return_sequences and self.return_state:
return output, hidden[-1]
elif self.return_sequences:
return output
elif self.return_state:
return output[:, -1, :], hidden[-1]
return self.sigmoid(result_output)
HIDDEN_DIM = 8
OUTPUT_DIM = 1
gru_model = GRUModel(
input_dim=VOCAB_SIZE,
hidden_units=HIDDEN_DIM,
output_dim=OUTPUT_DIM,
)
train_func(train_onehot, train_target, gru_model)
'LLM' 카테고리의 다른 글
| 3.3.6 [NLP] 자연어 딥러닝(언어 모델링) (0) | 2025.08.22 |
|---|---|
| 3.3.5 [NLP] 자연어 딥러닝(텍스트 분류) (0) | 2025.08.22 |
| 3.3.3 [NLP] 자연어 데이터 준비(자연어 임베딩) (0) | 2025.08.21 |
| 3.3.2 [NLP] 자연어 데이터 준비(텍스트 전처리) (8) | 2025.08.21 |
| 3.3.1 [NLP] 자연어 데이터 준비(개요 및 기초) (8) | 2025.08.18 |
