
Developer's Development
3.3.5 [NLP] 자연어 딥러닝(텍스트 분류) 본문
텍스트 분류
- 나이브 베이즈 분류기
나이브 베이즈는 단어 간 독립성을 가정하여 확률적으로 텍스트를 분류한다.
👉🏻 원리: 확률적 접근을 사용하며, 단어들 간의 독립성을 가정하여 각 단어가 주어진 클래스에서 등장할 확률을 곱하는 방식으로 분류를 수행한다.
👉🏻 장점
- 계산 비용이 낮고, 학습과 예측 속도가 매우 빠름
- 고차원(ex) 단어의 수가 많은 경우)에서도 상대적으로 잘 작동
- 간단한 구현과 이해가 용이함
👉🏻 단점
- 단어 간 상호 연관성(의존성)을 무시하기 때문에 복잡한 문맥을 반영하기 어려움
- 독립성 가정이 현실의 텍스트 데이터에서는 잘 맞지 않을 수 있음
👉🏻 선택 기준
- 초기 베이스라인 모델로 활용하거나, 빠른 프로토타이핑이 필요한 경우
- 데이터가 비교적 단순하고, 해석 가능성이 중요한 경우
- RNN 분류기
RNN 기반 분류기(LSTM/GRU 포함)는 시퀀스 데이터를 입력받아 텍스트 분류 작업을 수행한다.
👉🏻 원리: 시퀀스 데이터를 순차적으로 처리하여 문맥 정보를 반영하는 모델로, 내부 상태를 유지하며 이전 단어의 정보를 다음 단어 예측에 활용한다.
👉🏻 장점
- 텍스트의 순서와 문맥 정보를 효과적으로 반영
- 길이가 가변적인 시퀀스 처리에 유리함
- 감성 분석, 기계 번역 등에서 높은 성능을 발휘
👉🏻 단점
- 긴 시퀀스의 경우 기울기 소실/폭주 문제가 발생할 수 있음
- 순차 처리 방식으로 인해 병렬 처리가 어렵고 학습 속도가 느림
- 충분한 양의 데이터와 계산 자원이 필요
👉🏻 선택 기준
- 텍스트 내 순차적, 문맥적 정보가 중요한 작업(ex) 문장 단위 감성 분석)
- 데이터의 길이가 다양하고 순서 정보가 핵심인 경우
- CNN 분류기
CNN은 텍스트의 지역적 특징을 추출해 분류에 활용한다. 커널을 사용해 n-그램 단위의 정보를 학습한다.
👉🏻 원리: 텍스트의 지역적 특징(ex) n-gram 패턴)을 추출하기 위해 컨볼루션 필터를 사용하며, 이후 풀링을 통해 중요한 특징을 요약해 분류에 활용한다.
👉🏻 장점
- 병렬 처리가 가능해 학습 속도가 빠름
- 지역적 특징(문맥 내 특정 구절)을 효과적으로 포착
- RNN보다 계산 비용이 낮은 경우가 많음
👉🏻 단점
- 긴 문장이나 전역적 문맥 정보를 포착하는 데 한계가 있음
- 커널 사이즈, 필터 개수 등 하이퍼파라미터 설계가 성능에 큰 영향을 미침
👉🏻 선택 기준
- 텍스트 내 특정 패턴이나 구절의 중요도가 높은 경우
- 빠른 학습과 예측이 필요한 상황에서 사용
- 멀티 레이블 분류
하나의 입력 텍스트가 여러 개의 레이블에 속할 수 있는 경우를 처리한다.
실습 (나이브 베이즈 텍스트 분류기)
# 데이터 준비
corpus = [
"자연어 처리는 재미없다",
"Python이 더 쉬웠다",
"자연어 처리 공부는 재미없고 어렵다",
"Python 활용법을 더 열심히 찾아보자"
]
labels = [1, 0, 1, 0] # 자연어 관련은 1, Python 관련은 0
👉🏻 CountVectorizer
from sklearn.feature_extraction.text import CountVectorizer
from sklearn.naive_bayes import MultinomialNB
# CountVectorizer 벡터화
vectorizer = CountVectorizer()
X = vectorizer.fit_transform(corpus)
# 나이브 베이즈 분류
model = MultinomialNB()
model.fit(X, labels)
test_texts = [
"자연어 처리 너무 재미없다!",
"Python도 재미없었는데!"
]
X_test = vectorizer.transform(test_texts)
pred = model.predict(X_test)
pred # array([1, 0]) /자연어는 1, 파이썬은 0으로 잘 분류 (확률론적으로)
👉🏻 TfidVectorizer
from sklearn.feature_extraction.text import TfidfVectorizer
# TfidfVectorizer 벡터화
tfidf_vectorizer = TfidfVectorizer()
X_tfidf = tfidf_vectorizer.fit_transform(corpus)
model_tfidf = MultinomialNB()
model_tfidf.fit(X_tfidf, labels)
X_test_tfidf = tfidf_vectorizer.transform(test_texts)
pred_tfidf = model_tfidf.predict(X_test_tfidf)
pred_tfidf # array([1, 0])
실습 (RNN 텍스트 분류기)
# 데이터 준비
corpus = [
"자연어 처리는 재미있다",
"Python이 자연어 처리보다 쉽다",
"자연어 처리 공부는 어렵다",
"Python 활용법을 더 즐겁게 찾아보자"
]
labels = [1, 0, 0, 1] # 긍정에 1, 부정에 0# 데이터 전처리
# 토큰화
tokenized_corpus = [sentence.split() for sentence in corpus]
# 단어사전 생성
vocab = {}
for tokens in tokenized_corpus:
for token in tokens:
if token not in vocab:
vocab[token] = len(vocab) + 1
# 단어사전 기반으로 문장 인덱싱
indexed_corpus = []
for tokens in tokenized_corpus:
indexed_sent = [vocab[token] for token in tokens]
indexed_corpus.append(indexed_sent)
# 패딩 처리
max_seq_len = max(len(seq) for seq in indexed_corpus)
def pad_sequences(seq, max_len):
if len(seq) < max_len:
seq = seq + [0] * (max_len - len(seq))
return seq
padded_corpus = [pad_sequences(seq, max_seq_len) for seq in indexed_sent]import torch
import torch.nn as nn
# Torch Tensor 변환
# input, label을 torch의 tensor형으로 생성
inputs = torch.tensor(padded_corpus, dtype=torch.long)
labels = torch.tensor(labels, dtype=torch.float32).unsqueeze(1)
# RNN 기반 텍스트 분류기 모델 정의
class RNNClassifier(nn.Module):
def __int__(self, vocab_size, embed_size, hidden_size, num_classes):
super(RNNClassifier, self).__init__()
self.embedding = nn.Embedding(vocab_size, embed_size)
self.rnn = nn.RNN(embed_size, hidden_size, batch_first=True)
self.fc = nn.Linear(hidden_size, num_classes)
self.sigmoid = nn.Sigmoid()
def forward(self, x):
x = self.embedding(x)
_, hidden = self.rnn(x)
return self.sigmoid(self.fc(hidden[-1]))
# 모델 생성
VOCAB_SIZE = len(vocab) + 1
EMBED_SIZE = 128
HIDDEN_SIZE = 64
NUM_CLASSES = 1
model = RNNClassifier(
vocab_size=VOCAB_SIZE,
embed_size=EMBED_SIZE,
hidden_size=HIDDEN_SIZE,
num_classes=NUM_CLASSES
)
print(model)
"""
RNNClassifier(
(embedding): Embedding(15, 128)
(rnn): RNN(128, 64, batch_first=True)
(fc): Linear(in_features=64, out_features=1, bias=True)
(sigmoid): Sigmoid()
)
"""import torch.optim as optim
# 모델 학습
criterion = nn.BCELoss()
optimizer = optim.Adam(model.parameters(), lr=0.01)
epochs = 20
for epoch in range(epochs):
model.train()
optimizer.zero_grad()
outputs = model(inputs)
loss = criterion(outputs, labels)
loss.backward()
optimizer.step()
print(f'Epoch {epoch + 1}/{epochs} | Loss: {loss.item():.4f}') # Epoch 20만에 Loss 0.7137 -> 0.0023까지 떨어짐
# 테스트 데이터 전처리
test_texts = [
"자연어 처리는 재미있다",
"Python은 어렵다"
]
def preprocess_sentence(sentence, vocab, max_len):
tokens = sentence.split()
indices = [vocab.get(token, 0) for token in tokens]
indices = pad_sequences(indices, max_len)
return torch.tensor(indices, dtype=torch.long)
test_inputs = []
for sent in test_texts:
test_inputs.append(preprocess_sentence(sent, vocab, max_seq_len))
test_inputs = torch.stack(test_inputs)
# 모델 예측 (평가)
model.eval()
with torch.no_grad():
outputs = model(test_inputs)
print(outputs)
"""
tensor([[0.9974],
[0.5876]])
"""
실습 (멀티 레이블 텍스트 분류기)
# 데이터 준비
corpus = [
"자연어 처리는 재미있다",
"Python은 강력하다",
"자연어 처리와 Python을 함께 배우자!",
"딥러닝은 최신 기술이다",
"자연어 처리와 딥러닝이 미래다",
"Python과 딥러닝은 잘 맞는다"
]
labels = [
['자연어 처리'],
['Python'],
['자연어 처리', 'Python'],
['딥러닝'],
['자연어 처리', '딥러닝'],
['Python', '딥러닝']
]from sklearn.preprocessing import MultiLabelBinarizer
# 레이블 데이터 이진행렬 변환
mlb = MultiLabelBinarizer(classes=['자연어 처리', 'Python', '딥러닝'])
y_train = mlb.fit_transform(labels)
y_train
"""
array([[1, 0, 0],
[0, 1, 0],
[1, 1, 0],
[0, 0, 1],
[1, 0, 1],
[0, 1, 1]]) # MultiLabelBinarizer는 2개의 클래스를 가지기도 함!
"""from sklearn.feature_extraction.text import TfidfVectorizer
from sklearn.multiclass import OneVsRestClassifier
from sklearn.linear_model import LogisticRegression
# 텍스트 데이터 전처리
vectorizer = TfidfVectorizer()
X_train = vectorizer.fit_transform(corpus)
model = OneVsRestClassifier(LogisticRegression(max_iter=1000))
model.fit(X_train, y_train)# 테스트 데이터 생성
X_test = ["자연어 처리랑 딥러닝이랑 같이 공부하니까 재미있다!"]
y_test = [["자연어 처리", "딥러닝"]]
X_test = vectorizer.transform(X_test)
y_test = mlb.transform(y_test)
X_test, y_test
"""
(<1x16 sparse matrix of type '<class 'numpy.float64'>'
with 2 stored elements in Compressed Sparse Row format>,
array([[1, 0, 1]]))
"""
# 모델 추론
y_pred = model.predict(X_test)
y_pred # array([[1, 0, 0]])# 추론 결과 평가
from sklearn.metrics import classification_report, hamming_loss
print(classification_report(y_test, y_pred, target_names=mlb.classes_))
print(hamming_loss(y_test, y_pred))
"""
precision recall f1-score support
자연어 처리 1.00 1.00 1.00 1
Python 0.00 0.00 0.00 0
딥러닝 0.00 0.00 0.00 1
micro avg 1.00 0.50 0.67 2
macro avg 0.33 0.33 0.33 2
weighted avg 0.50 0.50 0.50 2
samples avg 1.00 0.50 0.67 2
0.3333333333333333
"""
실습 (NER(Named Entity Recognition))
데이터
- CoNLL - the Conference on Natural Language Learning
- https://github.com/Franck-Dernoncourt/NeuroNER
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import tensorflow as tf
import re
ner_train_path = tf.keras.utils.get_file("ner_train.txt", "https://raw.githubusercontent.com/Franck-Dernoncourt/NeuroNER/refs/heads/master/neuroner/data/conll2003/en/train.txt")
ner_test_path = tf.keras.utils.get_file("ner_test.txt", "https://raw.githubusercontent.com/Franck-Dernoncourt/NeuroNER/refs/heads/master/neuroner/data/conll2003/en/test.txt")
- 데이터 전처리
1. (word, ner) 변환
2. 토큰화
3. sequence 처리
4. padding 처리
# (word, ner) 태깅
def get_tagged_sentences(path):
temp = []
sentences = []
for line in open(path, 'r', encoding='utf-8'):
if line.startswith('-DOCSTART') or line[0] == '\n':
if len(temp) > 0:
sentences.append(temp)
temp = []
continue
word, pos, chunk, ner = line.split()
ner = re.sub("\n", '', ner) # 개행은 빈문자로 치환
word = word.lower() # 단어 소문자로
temp.append((word, ner))
return sentences
train_tagged_sents = get_tagged_sentences(ner_train_path)
test_tagged_sents = get_tagged_sentences(ner_test_path)
train_tagged_sents[:5] # 문장 단위로 튜플 형태로 가지고 있음# 입력 데이터/라벨 데이터 분리 (토큰화)
def get_sents_and_labels(tagged_sentences):
inputs, labels = [], []
for sentence in tagged_sentences:
tokens, ner = zip(*sentence) # senetence 펼쳐서 zip 처리
inputs.append(list(tokens))
inputs.append(list(ner))
return inputs, labels
train_inputs, train_labels = get_sents_and_labels(train_tagged_sents)
test_inputs, test_labels = get_sents_and_labels(test_tagged_sents)
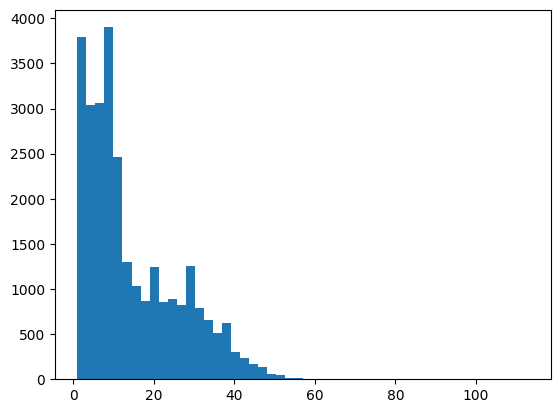
# 텍스트 길이 확인
train_len = [len(seq) for seq in train_inputs]
print('min-max:', np.min(train_len), "-", np.max(train_len))
print('mean:', np.mean(train_len))
print('median:', np.median(train_len))
plt.hist(train_len, bins=50)
plt.show()
"""
min-max: 1 - 113
mean: 14.501887329962253
median: 10.0
"""
# sequence, padding 처리
from tensorflow.keras.preprocessing.sequence import pad_sequences
from tensorflow.keras.preprocessing.text import Tokenizer
MAX_LEN = 50
VOCAB_SIZE = 10000
entity_tokenizer = Tokenizer(num_words=VOCAB_SIZE, oov_token="<OOV>")
entity_tokenizer.fit_on_texts(train_inputs)
X_train = entity_tokenizer.texts_to_sequences(train_inputs)
X_train = pad_sequences(X_train, maxlen=MAX_LEN, padding='pre', truncating='pre')
tag_tokenizer = Tokenizer()
tag_tokenizer.fit_on_texts(train_labels)
y_train = tag_tokenizer.texts_to_sequences(train_labels)
y_train = pad_sequences(y_train, maxlen=MAX_LEN, padding='pre', truncating='pre')
X_test = entity_tokenizer.texts_to_sequences(test_inputs)
X_test = pad_sequences(X_test, maxlen=MAX_LEN, padding='pre', truncating='pre')
y_test = tag_tokenizer.texts_to_sequences(test_labels)
y_test = pad_sequences(y_test, maxlen=MAX_LEN, padding='pre', truncating='pre')
tag_tokenizer.word_index
"""
{'o': 1,
'b-loc': 2,
'b-per': 3,
'b-org': 4,
'i-per': 5,
'i-org': 6,
'b-misc': 7,
'i-loc': 8,
'i-misc': 9}
"""
- 모델 생성 및 학습
from tensorflow.keras import layers, models
EMBED_DIM = 100
LATENT_DIM = 256
TAG_SIZE = len(tag_tokenizer.word_index)
input = layers.Input(shape=(MAX_LEN,))
x = layers.Embedding(VOCAB_SIZE + 1, EMBED_DIM)(input)
lstm = layers.LSTM(LATENT_DIM, return_sequences=True)
x = layers.Bidirectional(lstm)(x)
output = layers.Dense(TAG_SIZE + 1, activation='softmax')(x)
model = models.Model(input, output)
model.summary()
model.compile(
loss='sparse_categorical_crossentropy',
optimizer='adam',
metrics=['accuracy']
)
history = model.fit(
X_train,
y_train,
batch_size=128,
epochs=50,
validation_split=0.3
)
pd.DataFrame(history.history).plot()
plt.show()
loss, accuracy = model.evaluate(X_test, y_test)
loss, accuracy
"""
108/108 ━━━━━━━━━━━━━━━━━━━━ 3s 25ms/step - accuracy: 0.9784 - loss: 0.1529
(0.15287929773330688, 0.9784418344497681)
"""
- NER 예측
sample = ["Elon Musk is a founder of SpaceX and Neurallink"]
sample_seq = entity_tokenizer.texts_to_sequences(sample)
sample_padded = pad_sequences(sample_seq, maxlen=MAX_LEN)
pred_proba = model.predict(sample_padded)
pred = np.argmax(pred_proba, axis=-1)
pred
"""
1/1 ━━━━━━━━━━━━━━━━━━━━ 0s 40ms/step
array([[0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 3, 5, 1,
1, 1, 1, 1, 1, 1]], dtype=int64)
"""index2entity = entity_tokenizer.index_word
index2tag = tag_tokenizer.index_word
tokens = [index2entity.get(x, "?") for x in sample_padded[0]]
tags = [index2tag.get(x, "?") for x in pred[0]]
for token, tag in zip(tokens, tags):
if token != "?":
print(f'{token} --- {tag}')
"""
<OOV> --- b-per
<OOV> --- i-per
is --- o
a --- o
founder --- o
of --- o
<OOV> --- o
and --- o
<OOV> --- o
"""'LLM' 카테고리의 다른 글
| 3.3.7 [NLP] 자연어 딥러닝(신경망 기계 번역) (7) | 2025.08.26 |
|---|---|
| 3.3.6 [NLP] 자연어 딥러닝(언어 모델링) (0) | 2025.08.22 |
| 3.3.4 [NLP] 자연어 딥러닝(시퀀스 모델링) (1) | 2025.08.21 |
| 3.3.3 [NLP] 자연어 데이터 준비(자연어 임베딩) (0) | 2025.08.21 |
| 3.3.2 [NLP] 자연어 데이터 준비(텍스트 전처리) (8) | 2025.08.21 |