
Developer's Development
3.3.7 [NLP] 자연어 딥러닝(신경망 기계 번역) 본문
개요
기계번역은 한 언어의 텍스트를 다른 언어로 자동 변환하는 기술이다.
- 진화: 규칙 기반 → 통계적(SMT) → 신경망 기반(NMT)
- 구성 요소: 인코더, 디코더, 어텐션 메커니즘
- 활용: 글로벌 커뮤니케이션, 외국어 학습, 전자상거래 번역 등
Seq2Seq (Sequence-to-Sequence)
기계 번역 기법 중 하나인 Seq2Seq는 입력 시퀀스를 다른 (도메인의) 출력 시퀀스로 변환하는 딥러닝 모델로, 인코더-디코더 구조를 기반으로 한다. 주로 자연어 처리(NLP)에서 사용되며, 기계 번역, 텍스트 요약, 음성 인식 등 다양한 작업에서 활용된다.
- 주요 기여
1. 기계 번역의 혁신
: 기존의 통계적 기계 번역(SMT) 방식에 비해 신경망 기계번역(NMT)의 첫 주자로, 자연스럽고 유연한 번역을 가능하게 함
2. 인코더-디코더 아키텍처
: 입력 시퀀스를 인코더가 고정된 벡터로 인코딩하고, 디코더가 이를 기반으로 출력 시퀀스를 생성하는 구조로 도입
3. 후속 발전
Seq2Seq 이후 어텐션 메커니즘 및 트랜스포머 아키텍처의 등장으로 더욱 강력한 시퀀스 처리 모델이 개발될 수 있었음
- 주요 개념
1. 인코더
a. 입력 시퀀스를 처리해 고정된 크기의 벡터(context vector)로 인코딩한다.
b. 주로 RNN(LSTM, GRU) 구조를 사용한다.
c. 입력 시퀀스를 시계열로 처리하며 마지막 은닉 상태(hidden state)를 디코더로 전달한다.
2. 디코더
a. 인코더에서 전달받은 컨텍스트 벡터와 은닉 상태를 기반으로 출력 시퀀스를 생성한다.
b. 디코더는 순차적으로 다음 토큰을 예측하며, 이전에 생성된 토큰을 입력으로 사용한다.
- 작동 과정
1. 인코더: 입력 단어를 순차적으로 처리 → 컨텍스트 벡터 생성
2. 디코더: 컨텍스트 벡터와 이전 단계의 출력값(시작 시 <start> 토큰)을 기반으로 반복적으로(순차적으로) 출력값 생성
(종료 조건은 <end> 토큰이 생성되거나 사전에 정의된 최대 길이에 도달할 때)
* Teacher Forcing
: 학습 중 디코더에 이전에 생성된 예측값이 아니라 실제 정답 토큰을 입력으로 제공하여 빠르고 안정적인 학습을 돕는다.
* 손실 함수
: 출력 시퀀스의 각 토큰에 대해 예측값과 실제값의 차이를 계산하며, 보통 Categorical Crossentropy를 사용한다.
- 활용
기계번역: "How are you?" → "잘 지내니?"
텍스트 요약, 질의응답 시스템
→ Seq2Seq는 NLP의 중요한 기초 모델이다.
- 장점
시퀀스 길이가 가변적이므로 다양한 길이의 입력과 출력 처리 가능
- 한계
고정된 크기의 컨텍스트 벡터에 정보를 모두 압축하면 긴 시퀀스에서 정보 손실이 발생
(= 긴 문장에서 정보 손실 및 장기 의존성 문제 발생)
→ 해결책: 어텐션(Attention) 메커니즘 도입
* Attention Mechanism
: 인코더의 모든 은닉 상태를 활용하여 디코더가 출력 시점마다 중요한 입력 토큰에 집중하도록 한다.
: 성능을 크게 향상시키며, Transformer 기반 모델의 등장 배경이 된다.
* Transformer
: RNN 없이 Attention 메커니즘만을 사용하며 Seq2Seq의 최신 발전형이다.
실습 (seq2seq)
- Embedding Vector 준비
1. 영어 glove 임베딩 (사전 학습) 사용 / 6B tokens, 400K vocab, uncased, 100d
2. 한국어 임베딩 (초기 훈련)
!gdown 1qk-14tgVHPXT5jfRUE4Ua2ji4EXwS022
- 학습 데이터 준비
http://www.manythings.org/anki/
eng-kor 짝으로 이루어진 학습데이터
1. Encoder 입력 데이터 eng
- encoder_input_eng 준비 `I love you`
2. Decoder 출력 데이터 kor
- 학습용 teacher-forcing 모델
- decoder_input_kor `<sos> 난 널 사랑해`
- decoder_output_kor `난 널 사랑해 <eos>`
- 추론용 모델
!gdown 17X1AF5lusy-FP-Zadm-DDpbeKIZ1cWmH -O eng_kor.txteng_inputs = []
kor_inputs = []
kor_targets = []
with open('eng_kor.txt', 'r', encoding='utf-8') as f:
for line in f:
eng, kor, _ = line.split('\t')
kor_input = '<sos> ' + kor
kor_target = kor + ' <eos>'
eng_inputs.append(eng)
kor_inputs.append(kor_input)
kor_targets.append(kor_target)
len(eng_inputs), len(kor_inputs), len(kor_targets) # (5890, 5890, 5890)
- 토큰화
인코더(영어): 영문 토커나이저
디코더(한글): 국문 코커나이저
VOCAB_SIZE = 10000
👉🏻 영문 토큰화
from tensorflow.keras.preprocessing.text import Tokenizer
eng_tokenizer = Tokenizer(num_words = VOCAB_SIZE, oov_token='<oov>')
eng_tokenizer.fit_on_texts(eng_inputs)
eng_inputs_seq = eng_tokenizer.texts_to_sequences(eng_inputs)
eng_inputs_seq[2500:2505]
"""
[[2, 130, 38, 8, 268],
[2, 111, 150, 27, 2, 82],
[2, 300, 4, 213, 202],
[2, 206, 12, 54, 6, 60],
[2, 206, 12, 54, 6, 60]]
"""
for seq in eng_inputs_seq[2500:2505]:
print([eng_tokenizer.index_word[idx] for idx in seq])
"""
['i', 'speak', 'french', 'a', 'little']
['i', 'take', 'back', 'what', 'i', 'said']
['i', 'tried', 'to', 'make', 'friends']
['i', 'use', 'this', 'all', 'the', 'time']
['i', 'use', 'this', 'all', 'the', 'time']
"""
eng_num_words = min(VOCAB_SIZE, len(eng_tokenizer.word_index))
eng_max_len = max([len(seq) for seq in eng_inputs_seq])
👉🏻 국문 토큰화
# 기본값: filters='!"#$%&()*+,-./:;<=>?@[\\]^_`{|}~\t\n'
kor_tokenizer = Tokenizer(num_words=VOCAB_SIZE, oov_token='<oov>', filters='')
kor_tokenizer.fit_on_texts(kor_inputs + kor_targets)
kor_inputs_seq = kor_tokenizer.texts_to_sequences(kor_inputs)
kor_targets_seq = kor_tokenizer.texts_to_sequences(kor_targets)
# kor_tokenizer.index_word
kor_num_words = min(VOCAB_SIZE, len(kor_tokenizer.index_word))
kor_max_len = max([len(seq) for seq in kor_inputs_seq])
- 패딩처리
🐿️ 입출력의 크기 맞추기
인코더 padding = 'pre'
디코더 padding = 'post'
from tensorflow.keras.preprocessing.sequence import pad_sequences
eng_inputs_padded = pad_sequences(eng_inputs_seq, maxlen=eng_max_len, padding='pre')
kor_inputs_padded = pad_sequences(kor_inputs_seq, maxlen=kor_max_len, padding='post')
kor_targets_padded = pad_sequences(kor_targets_seq, maxlen=kor_max_len, padding='post')
- 모델 학습
`encoder + decoder(teach_forcing)` 구조의 모델 생성 및 학습
👉🏻 Embedding Layer
with open ('./glove.6B.100d.txt', 'r', encoding='utf-8') as f:
for i, vects in enumerate(f):
print(vects)
if i == 3:
breakimport numpy as np
def make_embedding_matrix(num_words, embedding_dim, tokenizer, file_path):
embedding_matrix = np.zeros((num_words + 1, embedding_dim))
pretrained_embedding = {}
with open(file_path, 'r', encoding='utf-8') as f:
for line in f:
word, *vects = line.split()
vects = np.array(vects, dtype=np.float32)
pretrained_embedding[word] = vects # 파일을 읽어와서 단어와 벡터가 매핑된 딕셔너리 형태로 생성
for word, index in tokenizer.word_index.items():
vects_ = pretrained_embedding.get(word)
if vects_ is not None:
embedding_matrix[index] = vects # 정수에 매핑되는 벡터를 생성
return embedding_matrix
EMBEDDING_DIM = 100
en_embedding_matrix = make_embedding_matrix(
eng_num_words,
EMBEDDING_DIM,
eng_tokenizer,
'glove.6B.100d.txt'
)
en_embedding_matrix.shape # (3201, 100)
eng_word_index = ['<pad>'] + list(eng_tokenizer.index_word.values())import pandas as pd
pd.DataFrame(en_embedding_matrix, index=eng_word_index)
- 인코더 모델
from tensorflow.keras import layers, models
LATENT_DIM = 512
encoder_inputs = layers.Input(shape=(eng_max_len,))
en_embedding_layer = layers.Embedding(eng_num_words+1, EMBEDDING_DIM, weights=[en_embedding_matrix])
x = en_embedding_layer(encoder_inputs)
encoder_outputs, h, c = layers.LSTM(LATENT_DIM, return_state=True)(x)
encoder_states = [h, c]
encoder_model = models.Model(inputs=encoder_inputs, outputs=encoder_states)
encoder_model.summary()
- 디코더 모델
decoder_inputs = layers.Input(shape=(kor_max_len,))
ko_embedding_layer = layers.Embedding(kor_num_words+1, EMBEDDING_DIM)
x = ko_embedding_layer(decoder_inputs)
decoder_lstm = layers.LSTM(LATENT_DIM, return_sequences=True, return_state=True)
x, h, c = decoder_lstm(x, initial_state=encoder_states)
decoder_dense = layers.Dense(kor_num_words+1, activation='softmax')
decoder_outputs = decoder_dense(x)
decoder_teacher_forcing_model = models.Model(
inputs=[encoder_inputs, decoder_inputs],
outputs=decoder_outputs
)
decoder_teacher_forcing_model.summary()
# 모델 시각화 목적 패키지 install
# graphviz는 https://graphviz.gitlab.io/download/에서 최신버전 다운로드 후 install (환경변수 세팅 x)
!pip install pydot pydotplus graphvizfrom tensorflow.keras.utils import plot_model
plot_model(decoder_teacher_forcing_model, show_shapes=True)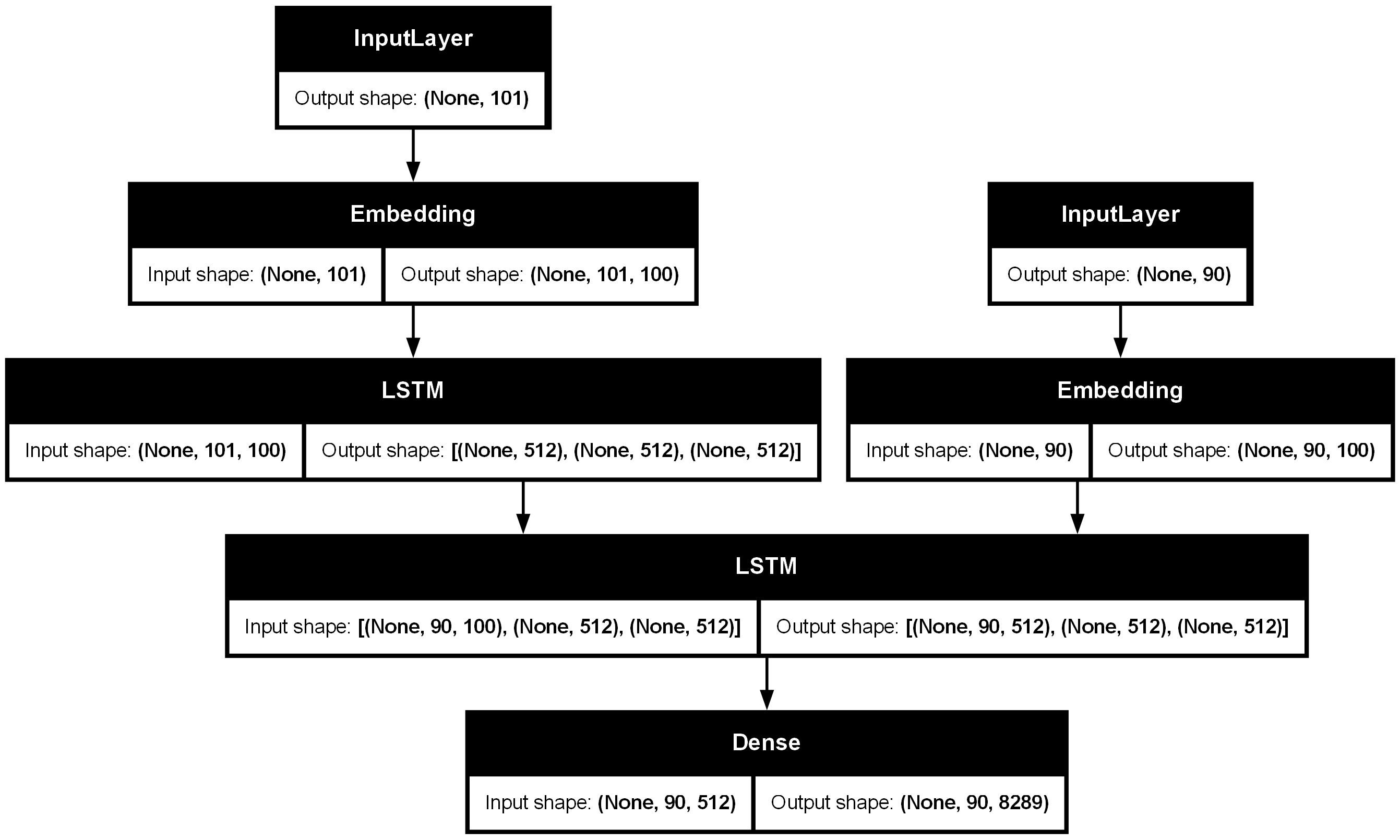
- 모델 학습
❗
VSCode에선 왕왕 느리니까, Google Colab에서 작업하던 파일 그대로 업로드해서 실행하기
T4 GPU로 런타임 유형 변경
decoder_teacher_forcing_model.compile(
loss='sparse_categorical_crossentropy',
optimizer='adam',
metrics=['accuracy']
)
history = decoder_teacher_forcing_model.fit(
[eng_inputs_padded, kor_inputs_padded],
kor_targets_padded,
batch_size=64,
epochs=70,
validation_split=0.2
)import matplotlib.pyplot as plt
pd.DataFrame(history.history).plot()
plt.show()
# 모델 저장
decoder_teacher_forcing_model.save('decoder_teacher_forcing_model.keras')
# 모델 로드
from tensorflow.models import load_model
decoder_teacher_forcing_model = load_model('decoder_teacher_forcing_model.keras')
- 모델 추론
encoder + decoder(interface) 구조의 모델로 추론
👉🏻 디코더 추론 모델
decoder_hidden_state = layers.Input(shape=(LATENT_DIM,))
decoder_cell_state = layers.Input(shape=(LATENT_DIM,))
decoder_states_inputs = [decoder_hidden_state, decoder_cell_state]
decoder_single_input = layers.Input(shape=(1,))
x = ko_embedding_layer(decoder_single_input)
x, h, c = decoder_lstm(x, initial_state=decoder_states_inputs)
decoder_states = [h, c]
decoder_outputs_ = decoder_dense(x)
decoder_inference_model = models.Model(
inputs=[decoder_single_input] + decoder_states_inputs,
outputs=[decoder_outputs_] + decoder_states
)
decoder_inference_model.summary()
plot_model(decoder_inference_model, show_shapes=True)
👉🏻 추론 함수
def translate(input_seq):
encoder_states_value = encoder_model.predict(input_seq)
decoder_states_value = encoder_states_value
sos_index = kor_tokenizer.word_index['<sos>']
eos_index = kor_tokenizer.word_index['<eos>']
target_seq = np.zeros((1, 1))
target_seq[0, 0] = sos_index
output_sentence = []
for _ in range(kor_max_len):
output_tokens, h, c = decoder_inference_model.predict([target_seq] + decoder_states_value)
pred_proba = output_tokens[0, 0, :]
pred_index = np.argmax(pred_proba)
if pred_index == eos_index:
break
if pred_index > 0:
word = kor_tokenizer.index_word[pred_index]
output_sentence.append(word)
target_seq[0, 0] = pred_index
decoder_states_value = [h, c]
return " ".join(output_sentence)print(eng_inputs[:1])
input_seq = eng_inputs_padded[:1]
translate(input_seq)
"""
['Go.']
1/1 ━━━━━━━━━━━━━━━━━━━━ 0s 153ms/step
1/1 ━━━━━━━━━━━━━━━━━━━━ 0s 119ms/step
1/1 ━━━━━━━━━━━━━━━━━━━━ 0s 34ms/step
'가.'
"""
# 5개 정도 더 확인
for _ in range(5):
idx = np.random.choice(len(eng_inputs_padded))
input_seq = eng_inputs_padded[idx:idx+1]
output_sent = translate(input_seq)
display("입력 영문:", eng_inputs[idx])
display("학습한 국문:", kor_inputs[idx])
display("추론한 국문:", output_sent)
display()for _ in range(5):
idx = np.random.choice(len(eng_inputs_padded))
input_seq = eng_inputs_padded[idx:idx+1]
output_sent = translate(input_seq)
display("입력 영문:", eng_inputs[idx])
display("학습한 국문:", kor_inputs[idx])
display("추론한 국문:", output_sent)
display()def translate_eng2kor(eng_text):
input_seq = eng_tokenizer.texts_to_sequences(eng_text)
input_seq = pad_sequences(input_seq, maxlen=eng_max_len)
return translate(input_seq)
# 학습하지 않은 데이터로 테스트
eng_texts = [
"My hair is black.",
"French is interesting.",
"I like bus.",
"Let\'s study",
"I ate sandwich"
]
for eng_text in eng_texts:
kor_text = translate_eng2kor([eng_text])
display(eng_text, kor_text) # 잘 나오는 것도, 잘 안나오는 것도 있음!
어텐션
기계 번역 기법 중 하나인 어텐션은 입력 시퀀스의 중요한 부분에 가중치를 부여해 번역 품질을 향상시키는 메커니즘이다.
RNN 및 LSTM, GRU와 같은 순환 신경망 모델이 가지고 있는 여러 문제점을 해결하기 위해 제안된 기술이며, 특히 자연어 처리(NLP) 및 시계열 데이터 처리와 같은 분야에서 매우 중요한 역할을 한다.
- 문제 해결: seq2seq 모델의 정보 손실 보완
[ 기존 RNN의 문제점 ]
1. 긴 시퀀스 학습의 어려움 (Long-Term Dependencies 문제)
2. 정보 병목 현상 (Information Bottleneck)
3. 병렬 처리 불가 (Lack of Parallelism)
4. 기억력의 한계 (Capacity Issue)
- 작동 방식
Attention 메커니즘은 입력 시퀀스의 모든 요소를 동일하게 처리하는 대신, 입력 단어의 중요한 부분에 가중치를 부여해 더욱 효율적으로 정보를 처리하는 방법이다.
이를 통해 모델은 특정 단어(또는 시점)에 더 많은 관심을 기울이며 필요한 정보를 선택적으로 사용할 수 있다.
1. 가중치 할당 (Attention Weights)
입력 시퀀스의 각 요소에 대해 얼마나 중요한지를 나타내는 가중치를 계산한다.
이 가중치는 쿼리(Query), 키(Key), 값(Value)의 연산을 통해 얻어진다.
- 쿼리(Query): 현재 시점의 은닉상태 (ex) 디코더에서 생성 중인 단어)
- 키(Key): 입력 시퀀스의 각 은닉상태
- 값(Value): 입력 시퀀스의 각 은닉상태
1) Attention 점수(Score)를 계산, 2) Softmax를 사용해 가중치로 변환, 3) 최종 Attention 값(Value) 생성
2. 동적 컨텍스트 생성
RNN처럼 고정된 크기의 컨텍스트 벡터를 생성하는 대신, Attention 메커니즘은 가중치가 적용된 입력의 가중합(Weighted Sum)을 동적으로 생성한다.
이는 출력 시퀀스의 각 스텝마다 새롭게 계산되며, 정보 병목 현상을 해결한다.
- Transformer Attention 종류
Self-Attention은 Q, K가 동일한 출처인 경우를 가리킨다.
1. Encoder Self-Attention: GlobalSelfAttention (Q, K, V 모두 인코더 상태를 사용)
2. Decoder Masked Self-Attention: CausalAttention (Q, K, V 모두 디코더 상태를 사용)
3. Encoder-Decoder Attention: CrossAttention (Q는 디코더의 출력을, K와 V는 인코더 상태를 사용)
- 장점
1. 정보 병목 현상 해결
2. 장기 의존성 처리
3. 모듈화 및 확장성
4. 해석 가능성 (InterPretablility)
- 활용 분야
기계번역, 텍스트 요약, 이미지 캡셔닝, 질의응답 시스템
실습 (Attention)
import torch
import torch.nn as nn
import torch.nn.functional as F
- Attention 가중치 계산
def attention(query, key, value):
# 1. Attention Score 계산 (Query - Key)
scores = torch.matmul(query, key.transpose(-2, -1))
print("Attention Score Shape:", scores.shape)
# 2. Softmax 적용
attention_weights = F.softmax(scores, dim=1)
print("Attention Weight Shape:", attention_weights.shape)
# 3. Attention value 계산 (=> 최종 context vector 계산)
context_vector = torch.matmul(attention_weights, value)
print("Context Vector Shape:", context_vector.shape)
return context_vector
vocab = {
"나는": 0,
"학원에": 1,
"간다": 2,
"<pad>": 3
}
vocab_size = len(vocab)
EMBEDDING_DIM = 4
inputs = ["나는", "학원에", "간다"]
inputs_ids = torch.tensor([[vocab[word] for word in inputs]])
inputs_ids # tensor([[0, 1, 2]])
# 1. 임베딩 적용
embedding_layer = nn.Embedding(vocab_size, EMBEDDING_DIM)
inputs_embedded = embedding_layer(inputs_ids)
# 2. 선형 변환
HIDDEN_DIM = 4
W_query = nn.Linear(EMBEDDING_DIM, HIDDEN_DIM)
W_key = nn.Linear(EMBEDDING_DIM, HIDDEN_DIM)
W_value = nn.Linear(EMBEDDING_DIM, HIDDEN_DIM)
input_query = W_query(inputs_embedded)
input_key = W_key(inputs_embedded)
input_value = W_value(inputs_embedded)
input_query.shape, input_key.shape, input_value.shape # (torch.Size([1, 3, 4]), torch.Size([1, 3, 4]), torch.Size([1, 3, 4]))
context_vector = attention(input_query, input_key, input_value)
context_vector
"""
Attention Score Shape: torch.Size([1, 3, 3])
Attention Weight Shape: torch.Size([1, 3, 3])
Context Vector Shape: torch.Size([1, 3, 4])
tensor([[[0.4532, 0.1573, 0.5742, 0.4456],
[0.7597, 0.3288, 0.9345, 0.6428],
[0.2053, 0.0282, 0.3066, 0.1972]]], grad_fn=<UnsafeViewBackward0>)
"""
- Seq2Seq 모델에 Attention 추가
class Attention(nn.Module):
def __init__(self, hidden_size):
super(Attention, self).__init__()
self.attn = nn.Linear(hidden_size * 2, hidden_size)
self.v = nn.Parameter(torch.rand(hidden_size))
def forward(self, hidden, encoder_outputs):
seq_len = encoder_outputs.shape[1]
hidden_expanded = hidden.unsqueeze(1).repeat(1, seq_len, 1)
energy = torch.tanh(self.attn(torch.cat((hidden_expanded, encoder_outputs), dim=2)))
attention_scores = torch.sum(self.v * energy, dim=2)
attention_weights = F.softmax(attention_scores, dim=1)
context_vector = torch.bmm(attention_weights.unsqueeze(1), encoder_outputs).squeeze(1)
return context_vector, attention_weights
class Seq2SeqWithAttention(nn.Module):
def __init__(self, input_dim, hidden_dim, output_dim):
super(Seq2SeqWithAttention, self).__init__()
self.encoder = nn.GRU(input_dim, hidden_dim, batch_first=True)
self.decoder = nn.GRU(hidden_dim, hidden_dim, batch_first=True)
self.attention = Attention(hidden_dim)
self.fc = nn.Linear(hidden_dim * 2, output_dim)
self.decoder_input_transform = nn.Linear(input_dim, hidden_dim)
def forward(self, encoder_input, decoder_input):
encoder_outputs, hidden = self.encoder(encoder_input)
context_vector, _ = self.attention(hidden[-1], encoder_outputs)
decoder_input_ = self.decoder_input_transform(decoder_input)
output, _ = self.decoder(decoder_input_, hidden)
combined = torch.cat((output, context_vector.unsqueeze(1)), dim=2)
return self.fc(combined)batch_size = 1
seq_len = 5
input_dim = 10
hidden_dim = 20
output_dim = 15
encoder_input = torch.randn(batch_size, seq_len, input_dim)
decoder_input = torch.randn(batch_size, 1, input_dim)
model = Seq2SeqWithAttention(input_dim, hidden_dim, output_dim)
model(encoder_input, decoder_input)
"""
tensor([[[ 0.4146, -0.0286, 0.0256, 0.1633, 0.0381, 0.1085, -0.0732,
-0.1124, 0.0481, -0.1960, -0.1456, 0.2977, 0.1054, -0.1160,
-0.1370]]], grad_fn=<ViewBackward0>)
"""
Input Feeding
기계 번역 기법 중 하나인 Input Feeding은 디코더에서 이전 시간 단계의 어텐션 정보와 현재 입력을 결합해 더 풍부한 문맥 정보를 제공하는 기법이다.
- 주요 개념
1. 문맥 정보 강화: 이전 어텐션 정보(컨텍스트 벡터)를 활용해 번역의 일관성과 정확성을 높임
2. 작동 방식
a. 현재 입력과 이전 컨텍스트 벡터를 결합
b. 디코더가 문맥 정보를 누적 학습
- 장점
1. 문맥 강화로 번역 품질 향상
2. 어텐션과 결합해 자연스러운 결과 생성
- 한계
계산 비용 및 모델 복잡성 증가
→ Input Feeding은 디코더의 성능을 개선해 더 자연스러운 번역과 텍스트 생성을 가능하게 한다.
자기회귀 속성과 Teacher Forcing 훈련 방법
자기회귀(Auto-regressive): 이전 출력이 현재 입력에 영향을 미침
Teacher Forcing: 훈련 중 실제 정답을 다음 입력으로 사용하는 방법
탐색(추론)
디코더가 최적의 출력 시퀀스를 생성하는 과정으로, 번역 품질을 높이는 다양한 전략을 사용한다.
- 주요 탐색 기법
1. 탐욕적 탐색 (Greedy Search)
- 각 단계에서 가장 높은 확률의 단어 선택
- 빠르지만 최적 결과 보장하지 않음
2. 빔 서치 (Beam Search)
- 여러 후보 시퀀스를 유지하며 최적 결과 탐색
- 더 높은 품질, 계산 비용 증가
3. 샘플링 (Sampling)
- 확률적으로 단어를 선택해 다양성 있는 출력 생성
- 활용 사례
- 기계번역: 문맥에 맞는 자연스러운 번역
- 텍스트 생성: 창의적인 문장 작성
- 질의응답: 적합한 답변 생성
- 탐색은 품질과 효율성을 균형 있게 조율하며 텍스트 생성의 핵심 역할을 한다.
실습 (Input Feeding 기법)
import torch
import torch.nn as nnclass InputFeedingDecoder(nn.Module):
def __init__(self, input_size, hidden_size, output_size):
super(InputFeedingDecoder, self).__init__()
self.hidden_size = hidden_size
self.embedding = nn.Embedding(output_size, input_size)
self.lstm = nn.LSTM(input_size + hidden_size, hidden_size)
self.fc = nn.Linear(hidden_size, output_size)
def forward(self, input, hidden, context):
embedded = self.embedding(input).unsqueeze(0)
lstm_input = torch.cat((embedded, context.unsqueeze(0)), dim=2)
output, hidden = self.lstm(lstm_input, hidden)
output = self.fc(output.squeeze(0))
return output, hidden
decoder = InputFeedingDecoder(input_size=10, hidden_size=20, output_size=30)
hidden = (torch.zeros(1, 1, 20), torch.zeros(1, 1, 20))
context = torch.zeros(1, 20)
input_token = torch.tensor([5])
output, hidden = decoder(input_token, hidden, context)
output.shape, hidden[0].shape # (torch.Size([1, 30]), torch.Size([1, 1, 20]))
실습 (Beam Search)
import torch
import torch.nn.functional as F
def beam_search(decoder, hidden, context, beam_width=3, max_length=10):
sequences = [[[], 1.0, hidden]]
for _ in range(max_length):
all_candidates = []
for seq, score, hidden in sequences:
decoder_input = torch.tensor([seq[-1] if seq else 0])
output, hidden = decoder(decoder_input, hidden, context)
top_probs, top_indices = torch.topk(F.softmax(output, dim=1), beam_width)
for i in range(beam_search):
candidate = (seq + [top_indices[0][i].item()], score * top_probs[0][i].item(), hidden)
all_candidates.append(candidate)
sequences = sorted(all_candidates, key=lambda x: x[1], reverse=True)[:beam_width]
return sequences[0][0]
실습 (Transformer by PyTorch)
!pip install bertviz
- Encoder
👉🏻 Self-Attention
# Self-Attention 시각화
from transformers import AutoTokenizer
from bertviz.transformers_neuron_view import BertModel # 사전학습된 BertModel 로드
from bertviz.neuron_view import show
model_ckpt = 'bert-base-uncased'
tokenizer = AutoTokenizer.from_pretrained(model_ckpt)
model = BertModel.from_pretrained(model_ckpt)
text = 'time flies like an arrow'
show(model, 'bert', tokenizer, text, display_mode='light', layer=0, head=0)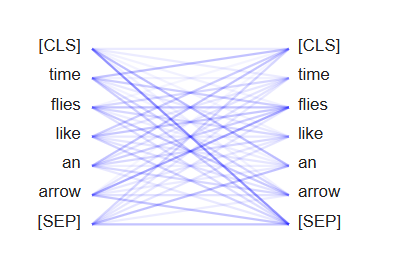
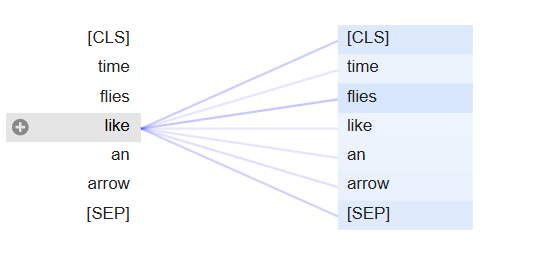
# Self-Attention 시각화 (문장 간 관계 포함)
from bertviz import head_view
from transformers import AutoModel
model = AutoModel.from_pretrained(model_ckpt, output_attentions=True)
sent1 = "time flies like an arrow"
sent2 = "fruit flies like an arrow"
viz_inputs = tokenizer(sent1, sent2, return_tensors='pt')
attention = model(**viz_inputs).attentions
sent2_start = (viz_inputs.token_type_ids == 0).sum(dim=1)
tokens = tokenizer.convert_ids_to_tokens(viz_inputs.input_ids[0])
head_view(attention, tokens, sent2_start, heads=[8])

Bert 모델 (bert-base-uncased)
- 12개의 레이어 (Transformer Layers)
-- 12개의 어텐션 헤드 (각 레이어마다)
--- 64차원 벡터 출력 (각 헤드마다)
---- 12개 헤드의 출력을 합쳐 768차원의 뉴런 벡터(hidden state) 생성
# 토큰화
inputs = tokenizer(text, return_tensors='pt', add_special_tokens=False)
inputs.input_ids # tensor([[ 2051, 10029, 2066, 2019, 8612]])# Embedding Layer 생성
import torch.nn as nn
from transformers import AutoConfig
config = AutoConfig.from_pretrained(model_ckpt)
emb = nn.Embedding(config.vocab_size, config.hidden_size)
emb # Embedding(30522, 768)
# Embedding 처리
inputs_embedded = emb(inputs.input_ids)
inputs_embedded.size() # torch.Size([1, 5, 768]) /하나의 문장, 다섯개의 토큰# Self-Attention 메커니즘
import torch
import torch.nn.functional as F
from math import sqrt
# 1. Attention score 계산
query = key = value = inputs_embedded
dim_k = key.size(-1)
scores = torch.bmm(query, key.transpose(1, 2)) / sqrt(dim_k) # 스케일링
# 2. Softmax 적용
weights = F.softmax(scores, dim=1)
# 3. Attention value 계산
attn_outputs = torch.bmm(weights, value)
attn_outputs.shape # torch.Size([1, 5, 768])# Self-Attention 함수
def attention(query, key, value):
dim_k = query.size(-1)
scores = torch.bmm(query, key.transpose(1, 2)) / sqrt(dim_k)
weights = F.softmax(scores, dim=1)
return torch.bmm(weights, value)
# Attention Layer
class AttentionHead(nn.Module):
def __init__(self, embed_dim, head_dim):
super().__init__()
self.q = nn.Linear(embed_dim, head_dim)
self.k = nn.Linear(embed_dim, head_dim)
self.v = nn.Linear(embed_dim, head_dim)
def forward(self, hidden_state):
return attention(
self.q(hidden_state),
self.k(hidden_state),
self.v(hidden_state)
)
# Multi-Head Attention
class MultiHeadAttention(nn.Module):
def __init__(self, config):
super().__init__()
embed_dim = config.hidden_size
heads_num = config.num_attention_heads
head_dim = embed_dim // heads_num
self.heads = nn.ModuleList([AttentionHead(embed_dim, head_dim) for _ in range(heads_num)])
self.output_layer = nn.Linear(embed_dim, embed_dim)
def forward(self, hidden_state):
output = torch.cat([h(hidden_state) for h in self.heads], dim=-1)
output = self.output_layer(output)
return output
multihead_attn = MultiHeadAttention(config)
attn_output = multihead_attn(inputs_embedded)
attn_output.size() # torch.Size([1, 5, 768])
- Feed-Fowrard
간단한 두 개 층으로 구성된 안전 연결 신경망
전체 임베딩 시퀀스를 하나의 벡터로 처리하지 않고 각 임베딩을 독립적으로 처리
GELU(Gaussian Error Linear Unit) 활성화 함수를 많이 사용
class FeedForward(nn.Module):
def __init__(self, config):
super().__init__()
self.linear1 = nn.Linear(config.hidden_size, config.intermediate_size)
self.linear2 = nn.Linear(config.intermediate_size, config.hidden_size)
self.gelu = nn.GELU()
self.dropout = nn.Dropout(config.hidden_dropout_prob)
def forward(self, x):
x = self.linear1(x)
x = self.gelu(x)
x = self.linear2(x)
x = self.dropout(x)
return x
feed_forward = FeedForward(config)
ff_outputs = feed_forward(attn_output)
ff_outputs.size() # torch.Size([1, 5, 768])
- 정규화를 반영한 EncoderLayer
👉🏻 사전 층 정규화를 적용
class TransformerEncoderLayer(nn.Module):
def __init__(self, config):
super().__init__()
self.layer_norm1 = nn.LayerNorm(config.hidden_size)
self.layer_norm2 = nn.LayerNorm(config.hidden_size)
self.attention = MultiHeadAttention(config)
self.feed_forward = FeedForward(config)
def forward(self, x):
hidden_state = self.layer_norm1(x)
x = x + self.attention(hidden_state)
x = x + self.feed_forward(self.layer_norm2(x))
return x
- 위치 임베딩 (Positional Encoding)
class Embeddings(nn.Module):
def __init__(self, config):
super().__init__()
self.token_embeddings = nn.Embedding(config.vocab_size, config.hidden_size)
self.position_embeddings = nn.Embedding(config.max_position_embeddings, config.hidden_size)
self.layer_norm = nn.LayerNorm(config.hidden_size, eps=1e-12)
self.dropout = nn.Dropout()
def forward(self, inputs_ids):
seq_len = inputs_ids.size(1)
position_ids = torch.arange(seq_len, dtype=torch.long).unsqueeze(0)
token_embeddings = self.token_embeddings(inputs_ids)
position_embeddings = self.position_embeddings(position_ids)
embeddings = token_embeddings + position_embeddings
embeddings = self.layer_norm(embeddings)
embeddings = self.dropout(embeddings)
return embeddings
- 완전한 인코더
class TransformerEncoder(nn.Module):
def __init__(self, config):
super().__init__()
self.embeddings = Embeddings(config)
self.layers = nn.ModuleList([TransformerEncoderLayer(config) for _ in range(config.num_hidden_layers)])
def forward(self, x):
x = self.embeddings(x)
for layer in self.layers:
x = layer(x)
return x
👉🏻 "Masked" Multi-head Self-Attention
👉🏻 Encoder-Decoder Attention
seq_len = inputs.input_ids.size(-1)
mask = torch.tril(torch.ones(seq_len, seq_len)).unsqueeze(0)
mask[0]
"""
tensor([[1., 0., 0., 0., 0.],
[1., 1., 0., 0., 0.],
[1., 1., 1., 0., 0.],
[1., 1., 1., 1., 0.],
[1., 1., 1., 1., 1.]])
"""
scores.masked_fill(mask==0, -float('inf'))
"""
tensor([[[ 2.6676e+01, -inf, -inf, -inf, -inf],
[-2.5965e-02, 2.7362e+01, -inf, -inf, -inf],
[-2.4433e-01, -5.2448e-02, 2.3241e+01, -inf, -inf],
[ 3.4082e-03, 3.5210e-01, 1.9143e+00, 2.7891e+01, -inf],
[ 2.4276e-01, -2.3076e-01, 6.2800e-02, 2.5864e-01, 2.8095e+01]]],
grad_fn=<MaskedFillBackward0>)
"""def attention(query, key, value, mask=None):
dim_k = query.size(-1)
scores = torch.bmm(query, key.transpose(1, 2)) / sqrt(dim_k)
if mask is not None:
scores.masked_fill(mask==0, -float('-inf'))
weights = F.softmax(scores, dim=-1)
return torch.bmm(weights, value)
'LLM' 카테고리의 다른 글
| 3.3.9 [LLM] 기초 및 응용 (10) | 2025.09.01 |
|---|---|
| 3.3.8 [NLP] 자연어 딥러닝(전이학습) (8) | 2025.08.27 |
| 3.3.6 [NLP] 자연어 딥러닝(언어 모델링) (0) | 2025.08.22 |
| 3.3.5 [NLP] 자연어 딥러닝(텍스트 분류) (0) | 2025.08.22 |
| 3.3.4 [NLP] 자연어 딥러닝(시퀀스 모델링) (1) | 2025.08.21 |